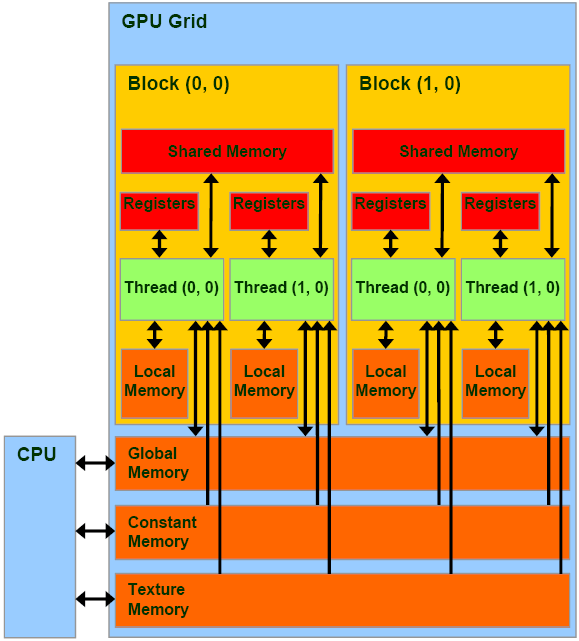
A device-global memory space on a GPU which caches constant data for all cores to read (and not write).
"Shared Memory" is one of the memory spaces in a GPU's memory model.
{kind=link}
(Caveat: The following information may be specific to NVIDIA GPUs; please correct as necessary)
Memory in this space is shared by all computational cores within the GPU chip. Each processing core does, however, has a specialized cache for constants - separate from the read-write L1 cache and the shared memory. In a sense, one can think of constant memory as an extra area of fast cache, limited to use for constant values.
The size of constant memory is very limited: on nVIDIA Maxwell and Pascal microarchitecture GPUs, it is 64 KiB for the whole device; and the per-core cache for constants is sized at 10 KiB only.
As its name indicates, constant memory is not altered during kernel execution. It does, however, have to be initialized somehow... in CUDA, this is done using the cudaMemcpyToSymbol() function.