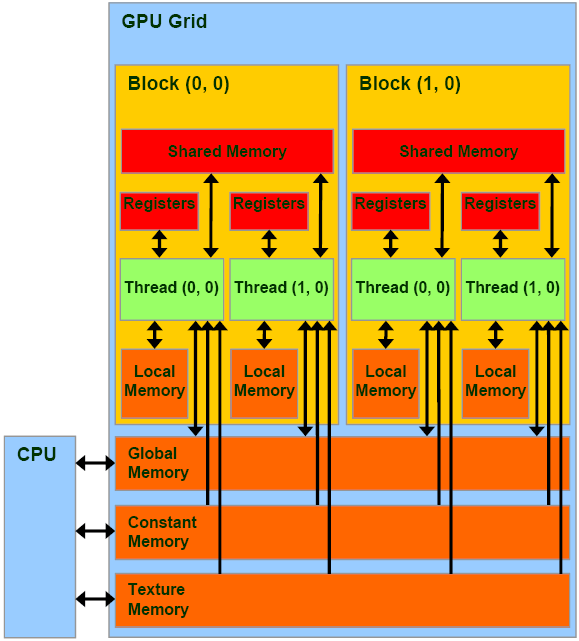
The memory space on a GPU computation core which is shared by all threads of a block in a work grid ("work-items" in a "work-group" of the grid in OpenCL parlance).
"Shared Memory" is one of the kinds of memory spaces in a GPU's memory model.
{kind=link}
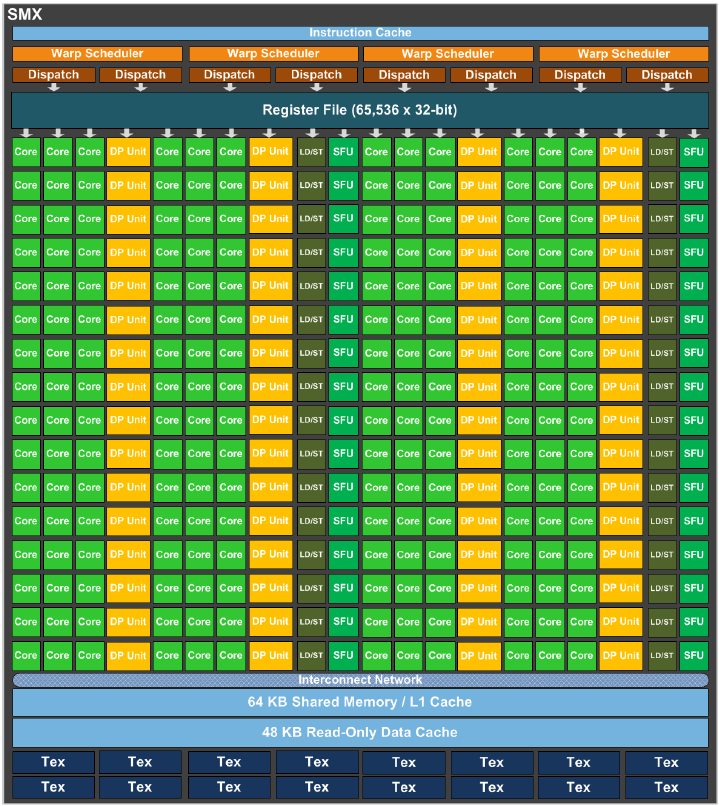
This space of memory, for a specific GPU thread ("work item" in OpenCL parlance) is located on the computational core within the GPU chip on which the thread is being executed (e.g. an SMX core on an nVIDIA Kepler GPU).
{kind=link}
{kind=link}
Shared memory is the "closest" (or fastest, if you will) memory space for a thread which is shared with other threads - all other threads in its block ("work-group" in OpenCL parlance), which are also executing on the same computational core.
Shared memory is similar in structure and behavior to L1 cache, and in fact these two are sometimes partially interchangeable. Hence accessing it is slower than using a thread's own registers, and there may be conflicts between accesses by other threads which degrade performance (named bank conflicts).
In OpenCL this memory space is called local memory which can cause confusion as "local memory" is something entirely different in CUDA.
OpenGL on the other hand uses the term "shared memory" in the same fashion as CUDA.