It's well known that accessing memory in a stride one fashion is best for performance.
In situations where
- I must access one region of memory for reading,
- I must access another region for writing, and
- I may only access one of the two regions in a stride one fashion,
should I prefer reading stride one or writing stride one?
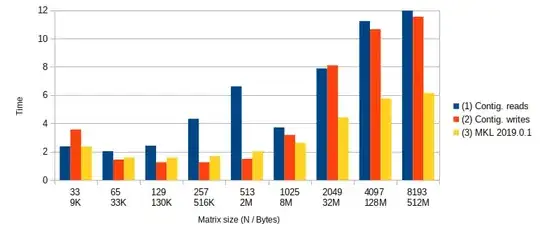
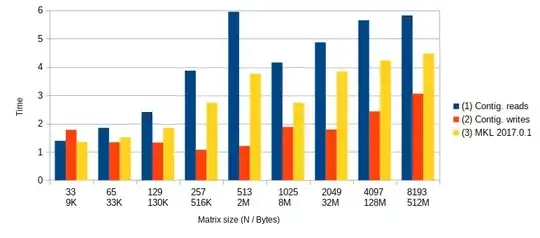
One simple, concrete example is a BLAS-like copy-and-permute operation like y := P x. The permutation matrix P is defined entirely by some permutation vector q(i). It has a corresponding inverse permutation vector qinv(i). One could code the required loop as y[qinv(i)] = x[i] or as y[i]=x[q(i)] where the former reads from x stride one and the latter writes to y stride one.
Ideally one could always code both possibilities, profile them under representative conditions, and choose the faster version. Pretend you could only code one version-- which access pattern would you always anticipate being faster based on the behavior of modern memory architectures? Does working in a threaded environment change your response?