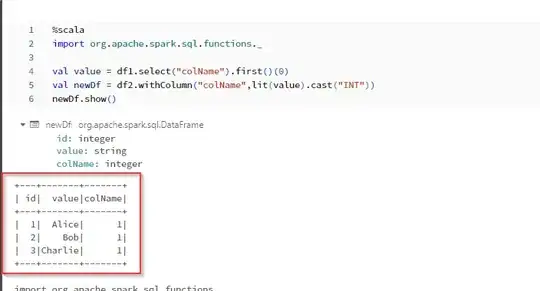
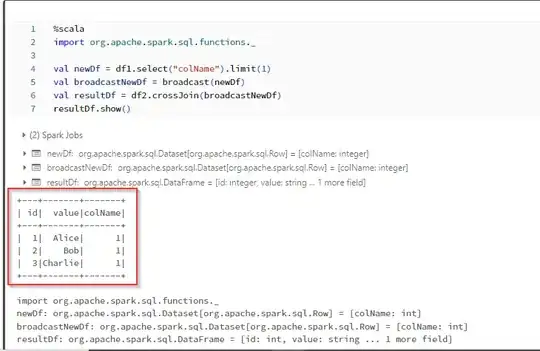
I have 2 large spark dataframes df1 and df2. df1 has a column with a colName name that has only one distinct value. I need to add this column to the df2. I'm wondering what would be the most efficient way to do that?
My idea is to use limit() or first() on the df1 and then crossJoin with the df2 but it would trigger an action.
val newDf = df1.select(colName).limit(1)
df2.crossJoin(newDf)