As per databricks documentaion
Control the output file size by below the Spark configuration spark.databricks.delta.autoCompact.maxFileSize.
Auto compaction can be enabled at the table or session level using the following settings:
Table property: delta.autoOptimize.autoCompact
SparkSession setting: spark.databricks.delta.autoCompact.enabled
Optimized writes can be enabled at the table or session level using the following settings:
Table setting: delta.autoOptimize.optimizeWrite
SparkSession setting: spark.databricks.delta.optimizeWrite.enabled
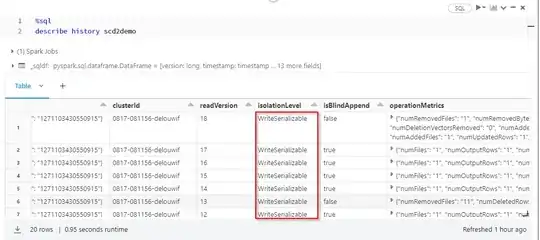
As you said OPTIMIZE explicitly can cause conflicts in some cases like UPDATE.
I have reproduced to UPDATE records and see if OPTIMIZE can cause conflicts.
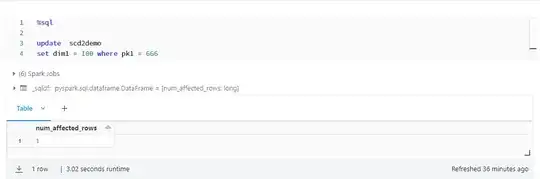
I have created a delta table and did an update on the table.
When I query the delta table spark engine fetch the latest version(.json) it gives the snapshot of the delta table.
Note: In delta table if we DELETE(or) UPDATE the older version will not be deleted because of the Time Travel feature in databricks
Versioining Logs:
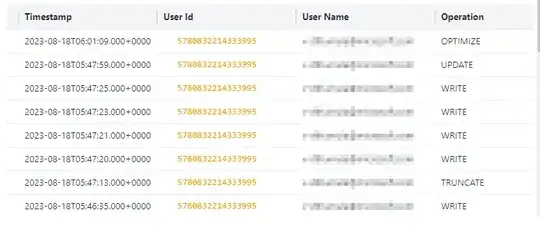
When you perform UPDATE in the file system new file gets added because we updated 1 REC, so it is going to retain the old file.
OPTIMIZE command mainly used to compact the smaller files in delta lake. Too many smaller files will impact performance.
The better approach is optimal partitions or size.
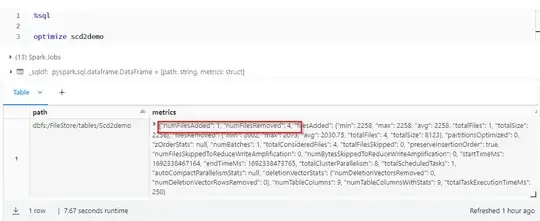 After Optimize:
After Optimize:
Optimize does file compacting all part files into 1 file and creating a .json as a reference to the latest snapshot of the delta table.
Know more about When to run OPTIMIZE