I'm trying to read csv files from ADLS gen2 (Microsoft Azure) and create delta tables . I'm able to successfully initiate a sparksession and read the csv files via spark in my local. But when I'm trying to write the dataframe as delta table I'm getting error saying Py4JJavaError: An error occurred while calling o120.save. :org.apache.spark.sql.delta.DeltaIllegalStateException: Versions (Vector(0, 0)) are not contiguous.
I've used all the combinations of different versions of spark, python and other related jars, but I'm still not able to create Delta tables from my local.
These are the configurations I've used to setup spark and read the data from ADLS gen2 Spark-3.3.0 Python-3.10 delta-spark-2.3 azure-storage-8.6.6 hadoop-azure-3.3.1 hadoop-azure-datalake-3.3.3 hadoop-common-3.3.3
This the code I tried.
from pyspark.sql import SparkSession
from delta.tables import *
spark =SparkSession.builder.master("local[*]")
.config("spark.jars.packages", "io.delta:delta-core_2.12:2.3.0")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.config("spark.delta.logStore.class", "org.apache.spark.sql.delta.storage.S3SingleDriverLogStore")
.config("spark.driver.memory", "4g")
.config("spark.executor.memory", "4g")
.config("spark.jars", r"C:\Users\Proem Sports\Documents\Jupyter notebooks\jars\mysql-connector-j-8.0.31.jar")
.config("spark.jars", r"C:\Users\Proem Sports\Documents\Jupyter notebooks\jars\azure-storage-8.6.6.jar")
.config("spark.jars", r"C:\Users\Proem Sports\Documents\Jupyter notebooks\jars\hadoop-azure-3.3.1.jar")
.config("spark.jars", r"C:\Users\Proem Sports\Documents\Jupyter notebooks\jars\hadoop-azure-datalake-3.3.3.jar")
.config("spark.jars", r"C:\Users\Proem Sports\Documents\Jupyter notebooks\jars\hadoop-common-3.3.3.jar")
.config("spark.sql.legacy.parquet.int96RebaseModeInRead", "CORRECTED")
.config("spark.sql.legacy.parquet.int96RebaseModeInWrite", "CORRECTED")
.config("spark.sql.legacy.parquet.datetimeRebaseModeInRead", "CORRECTED")
.config("spark.sql.legacy.parquet.datetimeRebaseModeInWrite", "CORRECTED")
.config("spark.sql.execution.arrow.pyspark.enabled", "TRUE")
.config("spark.sql.legacy.timeParserPolicy", "CORRECTED")
.config("spark.sql.warehouse.dir", r"C:\Users\Proem Sports\Documents\Jupyter notebooks\Dev_scripts\metastore_db")
.config("spark.sql.execution.arrow.pyspark.enabled", "true")
.config("spark.delta.commitInfo.merge.enabled", "true")
.config("fs.azure.createRemoteFileSystemDuringInitialization", "false")
.config("fs.azure", "org.apache.hadoop.fs.azure.NativeAzureFileSystem")
.config("fs.azure.account.auth.type", "SharedKey")
.config("fs.azure.account.key.proemdatalake.blob.core.windows.net", "account-key")
.enableHiveSupport()
.getOrCreate()
spark.conf.set("fs.azure.account.auth.type."+storage_account_name+".dfs.core.windows.net", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type."+storage_account_name+".dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id."+storage_account_name+".dfs.core.windows.net", client_id)
spark.conf.set("fs.azure.account.oauth2.client.secret."+storage_account_name+".dfs.core.windows.net", client_secret)
spark.conf.set("fs.azure.account.oauth2.client.endpoint."+storage_account_name+".dfs.core.windows.net", "https://login.microsoftonline.com/"+directory_id+"/oauth2/token")
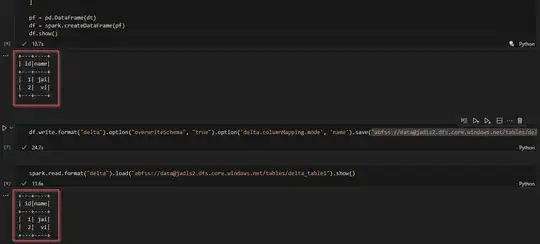
df=spark.read.format("csv").load("abfss://"container_name"@"storage_account_name".dfs.core.windows.net/RAW_DATA/MERHCHANDISE/MERCH_20230424_.csv",header=True,inferSchema=True)
df.write.format("delta").option("overwriteSchema", "true").option('delta.columnMapping.mode', 'name').save("abfss://"container_name"@"storage_account_name".dfs.core.windows.net/tables/delta_table1")
And the error I'm gettin is:
{Py4JJavaError: An error occurred while calling o120.save. : org.apache.spark.sql.delta.DeltaIllegalStateException: Versions (Vector(0, 0)) are not contiguous. at org.apache.spark.sql.delta.DeltaErrorsBase.deltaVersionsNotContiguousException(DeltaErrors.scala:852) at org.apache.spark.sql.delta.DeltaErrorsBase.deltaVersionsNotContiguousException$(DeltaErrors.scala:850) at org.apache.spark.sql.delta.DeltaErrors$.deltaVersionsNotContiguousException(DeltaErrors.scala:2293)}