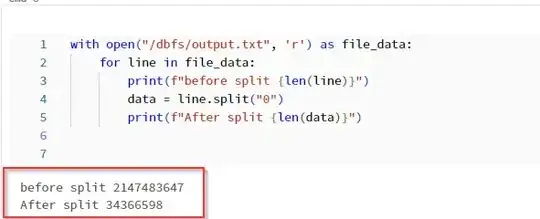
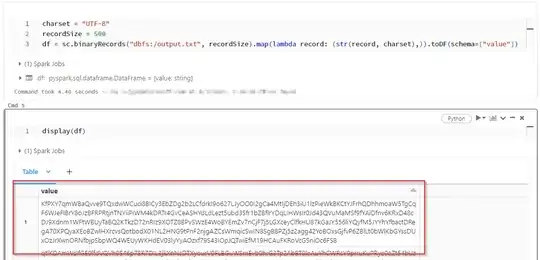
I'm running a python notebook in Azure Databricks. I am getting an IllegalArgumentException error when trying to add a line number with rdd.zipWithIndex(). The file is 2.72 GB and 1238951 lines (I think, text editor acts wonky with this big of a file). It ran for over 4 hours before it failed. I'm wondering if we are reaching some sort of size limit since the Exception is IllegalArgumentException. I'd like to know how to prevent this exception, and/or any way to make it faster. I was thinking I may have to break it down into smaller files. Any help is appreciated.
Code snippet
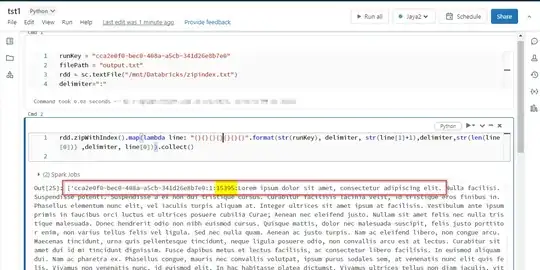
runKey = "cca2e0f0-bec0-408a-a5cb-341d26e8b7e0" # this is new id for every file
filePath = "/mnt/my_file_path/my_file.txt"
rdd = sc.textFile(filePath)
rdd = rdd.zipWithIndex().map(lambda line: "{}{}{}{}{}".format(str(runKey), delimiter, str(line[1]+1), delimiter, line[0]))
Output from error
File "<command-3893172145851236>", line 26, in OpenFileRDD
rdd = rdd.zipWithIndex().map(lambda line: "{}{}{}{}{}".format(str(runKey), delimiter, str(line[1]+1), delimiter, line[0]))
File "/databricks/spark/python/pyspark/rdd.py", line 2524, in zipWithIndex
nums = self.mapPartitions(lambda it: [sum(1 for i in it)]).collect()
File "/databricks/spark/python/pyspark/rdd.py", line 967, in collect
sock_info = self.ctx._jvm.PythonRDD.collectAndServe(self._jrdd.rdd())
File "/databricks/spark/python/lib/py4j-0.10.9-src.zip/py4j/java_gateway.py", line 1304, in __call__
return_value = get_return_value(
File "/databricks/spark/python/pyspark/sql/utils.py", line 117, in deco
return f(*a, **kw)
File "/databricks/spark/python/lib/py4j-0.10.9-src.zip/py4j/protocol.py", line 326, in get_return_value
raise Py4JJavaError(
py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe.
: org.apache.spark.SparkException: Job aborted due to stage failure: Task 4 in stage 1234573.0 failed 4 times, most recent failure: Lost task 4.3 in stage 1234573.0 (TID 46064376) (10.0.2.5 executor 5455): java.lang.IllegalArgumentException
at java.nio.CharBuffer.allocate(CharBuffer.java:334)
at java.nio.charset.CharsetDecoder.decode(CharsetDecoder.java:810)
at org.apache.hadoop.io.Text.decode(Text.java:412)
at org.apache.hadoop.io.Text.decode(Text.java:389)
at org.apache.hadoop.io.Text.toString(Text.java:280)
at org.apache.spark.SparkContext.$anonfun$textFile$2(SparkContext.scala:1065)
at scala.collection.Iterator$$anon$10.next(Iterator.scala:459)
at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
at org.apache.spark.api.python.PythonRDD$.writeIteratorToStream(PythonRDD.scala:442)
at org.apache.spark.api.python.PythonRunner$$anon$2.writeIteratorToStream(PythonRunner.scala:797)
at org.apache.spark.api.python.BasePythonRunner$WriterThread.$anonfun$run$1(PythonRunner.scala:521)
at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:2241)
at org.apache.spark.api.python.BasePythonRunner$WriterThread.run(PythonRunner.scala:313)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2978)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2925)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2919)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2919)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1357)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1357)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1357)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:3186)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:3127)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:3115)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:1123)
at org.apache.spark.SparkContext.runJobInternal(SparkContext.scala:2500)
at org.apache.spark.rdd.RDD.$anonfun$collect$1(RDD.scala:1071)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:165)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:125)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:454)
at org.apache.spark.rdd.RDD.collect(RDD.scala:1069)
at org.apache.spark.api.python.PythonRDD$.collectAndServe(PythonRDD.scala:260)
at org.apache.spark.api.python.PythonRDD.collectAndServe(PythonRDD.scala)
at sun.reflect.GeneratedMethodAccessor6189.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:380)
at py4j.Gateway.invoke(Gateway.java:295)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:251)
at java.lang.Thread.run(Thread.java:750)
Caused by: java.lang.IllegalArgumentException
at java.nio.CharBuffer.allocate(CharBuffer.java:334)
at java.nio.charset.CharsetDecoder.decode(CharsetDecoder.java:810)
at org.apache.hadoop.io.Text.decode(Text.java:412)
at org.apache.hadoop.io.Text.decode(Text.java:389)
at org.apache.hadoop.io.Text.toString(Text.java:280)
at org.apache.spark.SparkContext.$anonfun$textFile$2(SparkContext.scala:1065)
at scala.collection.Iterator$$anon$10.next(Iterator.scala:459)
at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
at org.apache.spark.api.python.PythonRDD$.writeIteratorToStream(PythonRDD.scala:442)
at org.apache.spark.api.python.PythonRunner$$anon$2.writeIteratorToStream(PythonRunner.scala:797)
at org.apache.spark.api.python.BasePythonRunner$WriterThread.$anonfun$run$1(PythonRunner.scala:521)
at org.apache.spark.util.Utils$.logUncaughtExceptions(Utils.scala:2241)
at org.apache.spark.api.python.BasePythonRunner$WriterThread.run(PythonRunner.scala:313)