We have Azure Synapse Link for Dataverse which enables continuouse export data from Dataverse to Azure Data Lake Storage Gen2 (CSV format).
Main source of data is D365 CRM. All the files contains columns SinkModifiedOn, and IsDelete.
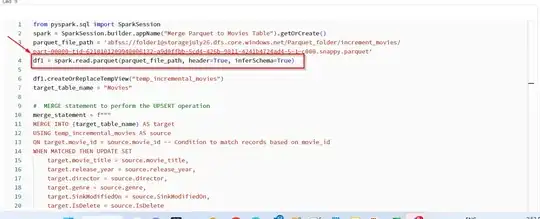
Current solution implies reading all the CSV files, using databricks python notebook and creating the dfs. Then converting these dfs as PARQUET files and laoding in another datalake.
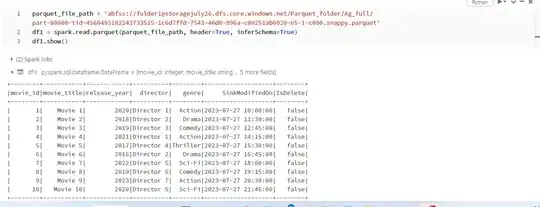
Next step is to read the PARQUET files using the below code. So, it always refers to the full load from csv to parquet. and created tables are PARQUET foramts (not DELTA)
%sql
USE CATALOG ${personal.catalog};
CREATE SCHEMA IF NOT EXISTS ${personal.schema};
-- DROP TABLE IF EXISTS ${personal.schema}.${personal.source}_${personal.table};
CREATE TABLE IF NOT EXISTS ${personal.schema}.${personal.source}_${personal.table}
USING PARQUET
LOCATION 'abfss://${personal.schema}@${personal.storage_account_name}.dfs.core.windows.net/${personal.source}/${personal.table}'
OPTIONS(recursiveFileLookup = true);
ALTER TABLE ${personal.schema}.${personal.source}_${personal.table} SET TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.minReaderVersion' = '2',
'delta.minWriterVersion' = '5')
My goal:
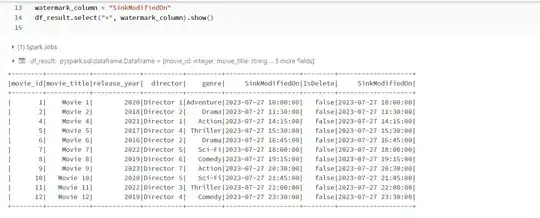
I would like to achieve the incremental load. But Im not sure how to do so. My thinkig of way is to create the watermark table and identify the changes in the CSV files and create df out of them. Next, output those as PARQUET files as its in the current work flow and load them in another datalake. As of next steps Im not sure how to continue.
Any help or tips how can I achiave this will be appreciated