The below code in PySpark that will perform an incremental load for two Delta tables named "employee_table" and "department_table".
Here is the initial load for the "employee_table" and "department_table".
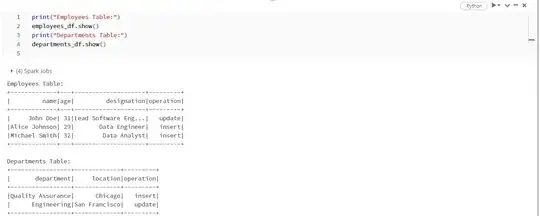
The Below is the Initial load files for 2 tables.
As you said you read all the files under delta table folder in ADLS location.
As an example I have *INSERT and UPDATE operations as part of the incremental load process.
The below is code doing the incremental load and writing the output to the ADLS file path as parquet.
new_employees_data = [("Alice Johnson", 29, "Data Engineer"),
("Michael Smith", 32, "Data Analyst")]
new_departments_data = [("Quality Assurance", "Chicago")]
updated_employee_data = [("John Doe", 31, "Lead Software Engineer")]
updated_department_data = [("Engineering", "San Francisco")]
new_employees_df = spark.createDataFrame(new_employees_data, ["name", "age", "designation"])
new_departments_df = spark.createDataFrame(new_departments_data, ["department", "location"])
updated_employee_df = spark.createDataFrame(updated_employee_data, ["name", "age", "designation"])
updated_department_df = spark.createDataFrame(updated_department_data, ["department", "location"])
output_path = "abfss://folder1@synapseadlsgen2july23.dfs.core.windows.net/From_Databricks_delta_new/Incremental_file/"
"employees" table.
new_employees_df = new_employees_df.withColumn("operation", lit("insert"))
updated_employee_df = updated_employee_df.withColumn("operation", lit("update"))
employees_incremental_data = new_employees_df.union(updated_employee_df)
employees_incremental_data.write \
.format("parquet") \
.mode("append") \
.save(output_path + "employees")
"departments" table.
new_departments_df = new_departments_df.withColumn("operation", lit("insert"))
updated_department_df = updated_department_df.withColumn("operation", lit("update"))
departments_incremental_data = new_departments_df.union(updated_department_df)
departments_incremental_data.write \
.format("parquet") \
.mode("append") \
.save(output_path + "departments")
For the "employees" table, two DataFrames are created: new_employees_df for new employees and updated_employee_df for updated employee information.
For the "departments" table, two DataFrames are created new_departments_df for new departments and updated_department_df for updated department information.
An "operation" column is added to each DataFrame to indicate whether a record is an "insert" or an "update".
Reading the incremental data from ADLS as parquet and writing to DELTA tables in databricks:
The code reads Parquet files from Azure Data Lake Storage (ADLS) into Spark DataFrames, and then register those DataFrames as Delta tables.
Delta is the extension of Parquet files that provides additional features like ACID transactions, schema evolution, and more.
The DataFrames are written back to the store in Delta format using the write method.
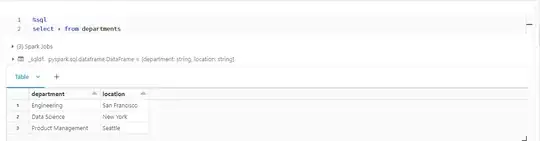
These Delta tables can be queried using SQL or Spark DataFrame API and will benefit from Delta's ACID properties.
input_path = "abfss://folder1@synapseadlsgen2july23.dfs.core.windows.net/From_Databricks_delta_new/Incremental_file/"
employees_df = spark.read.format("parquet").load(input_path + "employees")
departments_df = spark.read.format("parquet").load(input_path + "departments")
employees_df.write \
.format("delta") \
.mode("overwrite") \
.saveAsTable("employees")
departments_df.write \
.format("delta") \
.mode("overwrite") \
.saveAsTable("departments")