First, make sure you have python between these version [3.6 - 3.9]
While creating apache spark pool select spark version in such a way that python version should be between as mentioned above.
Next, create a notebook in your synapse workspace add following code.
To get data from Azure file Share , you need to download it locally and read into pandas then to spark dataframe.
Add below code blocks into you notebook.
pip install azure-storage-file-share==12.1.0 qvd
installs required package.
from qvd import qvd_reader
localpath="tmp.qvd"
connection_string = "Your_conn_string_to_storage_account"
share_name = "Your_file_share_name"
directory_name = "dir_name_in_fileshare"
file_name = "Airlines.qvd"
def download_from_file_storage():
share_client = ShareClient.from_connection_string(connection_string, share_name)
file_client = share_client.get_file_client(directory_name + '/' + file_name)
with open(localpath, "wb") as file:
download_stream = file_client.download_file()
file.write(download_stream.readall())
download_from_file_storage()
Function which downloads file into local file system.
from pyspark.sql.functions import col
df = qvd_reader.read(localpath)
s_df = spark.createDataFrame(df)
s_df = s_df.withColumn("AirlineId",col("%Airline ID")).drop(col("%Airline ID"))
display(s_df)
Here, reading qvd file from local and converting it to spark dataframe.
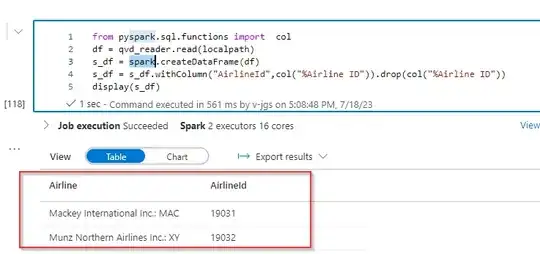
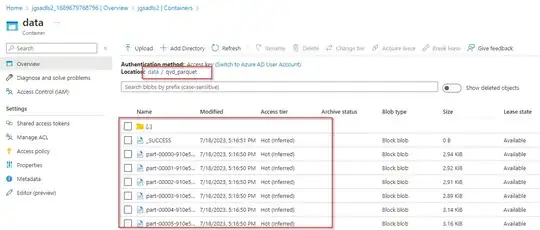
Next, using linked service writing that data to adls2 storage as parquet.

linkedServiceName_var = "adls2link"
spark.conf.set("fs.azure.account.auth.type", "SAS")
spark.conf.set("fs.azure.sas.token.provider.type", "com.microsoft.azure.synapse.tokenlibrary.LinkedServiceBasedSASProvider")
spark.conf.set("spark.storage.synapse.linkedServiceName", linkedServiceName_var)
raw_container_name = "data"
raw_storageaccount_name = "jgsadls2"
relative_path = "qvd_parquet"
path = f"abfss://{raw_container_name}@{raw_storageaccount_name}.dfs.core.windows.net/qvd_parquet"
s_df.write.parquet(path)
Before, executing this you need to create linked service to your adls storage.
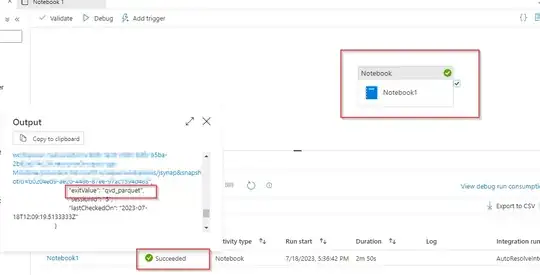
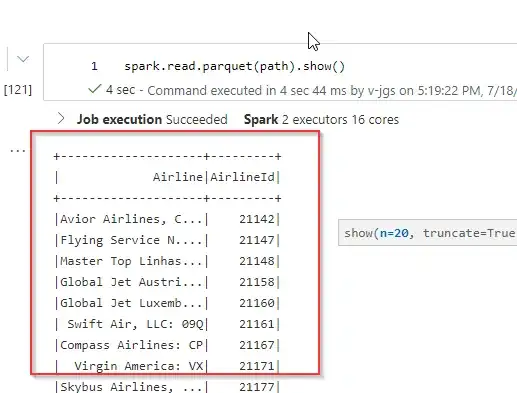
Output:
and
If you want to use this in pipeline, add this notebook to pipeline with exit value as path and run it.
Then take the path in output of the pipeline and use it further.