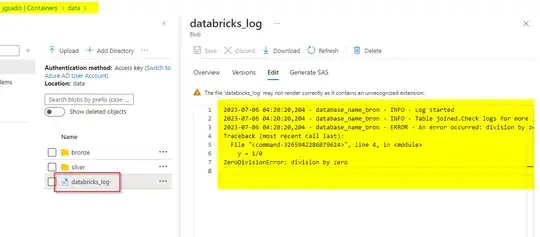
I'm trying to write a logging system in databricks for a few jobs we need to run. Currently I'm setting up a logger and log the files in-memory -> log_stream = io.StringIO()
All functions are covered in a try, except block to catch info or exception in the logger and log them. But it is also used to have certainty that the last block of the notebook will run. Which is needed because this contains the code that uploads the in-memory file to a blob storage.
However, I feel this method is quite 'ugly', since every code needs to be covered in a try, except block.
Are their any methods to either always run the last block of the notebook even when an part of the code completly fails/errors. Or is there another method to secure that the logfile is directly uploaded in case of any errors?
current code:
-- logging --
log_stream = io.StringIO()
logger = logging.getLogger(database_name_bron)
logger.setLevel(logging.DEBUG)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler = logging.StreamHandler(log_stream)
handler.setLevel(logging.DEBUG)
handler.setFormatter(formatter)
if logger.hasHandlers():
logger.handlers.clear()
logger.addHandler(handler)
-- code block example --
try:
table = output_dict['*'].select( \
col('1*').alias('1*'), \
col('2*').alias('2*'), \
col('3*').alias('3*'), \
col('4*').alias('4*'), \
col('5*').alias('5*'), \
)
#join tabellen
table2= table2.join(table1, table2.5* == table1.4*, 'left')
logger.info('left join van table 1en table2')
except Exception as e:
logger.exception(f"Een error heeft plaatsgevonden tijdens het joinen van table1 en table2: {e}")
-- upload block --
#extraheer log data
log_content = log_stream.getvalue()
#upload data naar de blob storage
dbutils.fs.put(f"abfss://{container_name}@{storage_account}.dfs.core.windows.net/{p_container_name}", log_content, overwrite=True)
#netjes afsluiten van de handler
logger.removeHandler(handler)
handler.close()