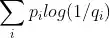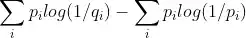Given two discrete probability distributions P and Q, containing zero values in some bins, what is the best approach to avoid the Kullback–Leibler divergence equal to infinite (and therefore getting some finite value, between zero and one)?
Here below an example of calculation (with Matlab) of the Kullback–Leibler divergence between P and Q, which gives an infinite value. I am tempted to manually remove "NaNs" and "Infs" from "log2( P./Q )", but I am afraid this is not correct. In addition, I am not sure that smoothing the PDFs could solve the issue...
% Input
A =[ 0.444643925792938 0.258402203856749
0.224416517055655 0.309641873278237
0.0730101735487732 0.148209366391185
0.0825852782764812 0.0848484848484849
0.0867743865948534 0.0727272727272727
0.0550568521843208 0.0440771349862259
0.00718132854578097 0.0121212121212121
0.00418910831837223 0.0336088154269972
0.00478755236385398 0.0269972451790634
0.00359066427289048 0.00110192837465565
0.00538599640933573 0.00220385674931129
0.000598444045481747 0
0.00299222022740874 0.00165289256198347
0 0
0.00119688809096349 0.000550964187327824
0 0.000550964187327824
0.00119688809096349 0.000550964187327824
0 0.000550964187327824
0 0.000550964187327824
0.000598444045481747 0
0.000598444045481747 0
0 0
0 0.000550964187327824
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0.000550964187327824
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0.00119688809096349 0.000550964187327824];
P = A(:,1); % sum(P) = 0.999999999
Q = A(:,2); % sum(Q) = 1
% Calculation of the Kullback–Leibler divergence
M = numel(P);
P = reshape(P,[M,1]);
Q = reshape(Q,[M,1]);
KLD = nansum( P .* log2( P./Q ) )
% Result
>> KLD
KLD =
Inf
>> log2( P./Q )
ans =
0.783032102845145
-0.46442172001576
-1.02146721017182
-0.0390042690948072
0.254772785478407
0.320891675991577
-0.755211303094213
-3.00412460068336
-2.49545202929328
1.70422031554308
1.28918281626424
Inf
0.856223408988134
NaN
1.11925781482192
-Inf
1.11925781482192
-Inf
-Inf
Inf
Inf
NaN
-Inf
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
-Inf
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
1.11925781482192
FIRST EDITING
So far, I found a theoretical argument, which partially solve my issue, but still, the infinite values remain when
% if P_i > 0 and Q_i = 0, then P_i*log(P_i/0) = Inf
The following is what I implemented by considering the conventions described at pag.19 of "Elements of Information Theory, 2nd Edition Thomas M. Cover, Joy A. Thomas":
clear all; close all; clc;
% Input
A =[ 0.444643925792938 0.258402203856749
0.224416517055655 0.309641873278237
0.0730101735487732 0.148209366391185
0.0825852782764812 0.0848484848484849
0.0867743865948534 0.0727272727272727
0.0550568521843208 0.0440771349862259
0.00718132854578097 0.0121212121212121
0.00418910831837223 0.0336088154269972
0.00478755236385398 0.0269972451790634
0.00359066427289048 0.00110192837465565
0.00538599640933573 0.00220385674931129
0.000598444045481747 0
0.00299222022740874 0.00165289256198347
0 0
0.00119688809096349 0.000550964187327824
0 0.000550964187327824
0.00119688809096349 0.000550964187327824
0 0.000550964187327824
0 0.000550964187327824
0.000598444045481747 0
0.000598444045481747 0
0 0
0 0.000550964187327824
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0.000550964187327824
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0.00119688809096349 0.000550964187327824];
P = A(:,1);
Q = A(:,2);
% some processing
M = numel(P);
P = reshape(P,[M,1]);
Q = reshape(Q,[M,1]);
% At Pag.19 of "Elements of Information Theory, 2nd Edition Thomas M. Cover, Joy A. Thomas"
% (Section: 2.3 Relative Entropy and Mutual Information)
% there are three conventions to be used in the calculation of the Kullback–Leibler divergence
idx1 = find(P==0 & Q>0); % index for convention 0*log(0/q) = 0
idx2 = find(P==0 & Q==0); % index for convention 0*log(0/0) = 0
idx3 = find(P>0 & Q==0); % index for convention p*log(p/0) = Inf
% Calculation of the Kullback–Leibler divergence,
% by applying the three conventions described in "Elements of Information Theory..."
tmp = P .* log2( P./Q );
tmp(idx1) = 0; % convention 0*log(0/q) = 0
tmp(idx2) = 0; % convention 0*log(0/0) = 0
tmp(idx3) = Inf; % convention p*log(p/0) = Inf
KLD = sum(tmp)
The result is still "Inf" since some elements in the distribution Q are zeros, while the corresponding elements of P are greater than zero:
KLD =
Inf
SECOND EDITING, i.e. after the first @Meferne Answer (PLEASE, DO NOT USE THIS CODE - IT LOOKS LIKE I MISUNDERSTOOD THE @Meferne COMMENT)
I tried to apply the softmax function to the distribution Q (in order to have Q_i>0), but the distribution Q changes considerably:
P = A(:,1);
Q = A(:,2);
% some processing
M = numel(P);
P = reshape(P,[M,1]);
Q = reshape(Q,[M,1]);
Q = softmax(Q); % <-- this is equivalent to: Q = softmax(Q) = exp(Q)/sum(exp(Q))
% At Pag.19 of "Elements of Information Theory, 2nd Edition Thomas M. Cover, Joy A. Thomas"
% (Section: 2.3 Relative Entropy and Mutual Information)
% there are three conventions to be used in the calculation of the Kullback–Leibler divergence
idx1 = find(P==0 & Q>0); % index for convention 0*log(0/q) = 0
idx2 = find(P==0 & Q==0); % index for convention 0*log(0/0) = 0
idx3 = find(P>0 & Q==0); % index for convention p*log(p/0) = Inf
% Calculation of the Kullback–Leibler divergence,
% by applying the three conventions described in "Elements of Information Theory..."
tmp = P .* log2( P./Q );
tmp(idx1) = 0; % convention 0*log(0/q) = 0
tmp(idx2) = 0; % convention 0*log(0/0) = 0
tmp(idx3) = Inf; % convention p*log(p/0) = Inf
KLD = sum(tmp)
...leading to a KLD value greater than 1:
KLD =
2.9878
THIRD EDITING, i.e. after further explanatory comments of @Meferne (PLEASE USE THIS CODE IF NEEDED!)
clear all; close all; clc;
format long G % <-- to see better that the "sum(Qtmp)" is greater than 1
% Input
A =[ 0.444643925792938 0.258402203856749
0.224416517055655 0.309641873278237
0.0730101735487732 0.148209366391185
0.0825852782764812 0.0848484848484849
0.0867743865948534 0.0727272727272727
0.0550568521843208 0.0440771349862259
0.00718132854578097 0.0121212121212121
0.00418910831837223 0.0336088154269972
0.00478755236385398 0.0269972451790634
0.00359066427289048 0.00110192837465565
0.00538599640933573 0.00220385674931129
0.000598444045481747 0
0.00299222022740874 0.00165289256198347
0 0
0.00119688809096349 0.000550964187327824
0 0.000550964187327824
0.00119688809096349 0.000550964187327824
0 0.000550964187327824
0 0.000550964187327824
0.000598444045481747 0
0.000598444045481747 0
0 0
0 0.000550964187327824
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0.000550964187327824
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0 0
0.00119688809096349 0.000550964187327824];
P = A(:,1);
Q = A(:,2);
% some processing
M = numel(P);
P = reshape(P,[M,1]);
Q = reshape(Q,[M,1]);
% renormalize the distribution Q (after the comments of @Meferne)
epsilon = 1e-12;
Qtmp = Q; % <-- assign temporarily the distribution Q to another array
Q = []; % <-- delete/empty Q
Qtmp = Qtmp + epsilon; % <-- add a small positive number (epsilon) to all Q_i
sum(Qtmp) % <-- just to check: the sum of all Q_i is now greater than 1 (as expected)
Q = Qtmp./sum(Qtmp); % <-- renormalize the distribution Q
sum(Q) % <-- just to check: the sum of all Q_i is again equal to 1 (as expected)
% At Pag.19 of "Elements of Information Theory, 2nd Edition Thomas M. Cover, Joy A. Thomas"
% (Section: 2.3 Relative Entropy and Mutual Information)
% there are three conventions to be used in the calculation of the Kullback–Leibler divergence
idx1 = find(P==0 & Q>0); % index for convention 0*log(0/q) = 0
idx2 = find(P==0 & Q==0); % index for convention 0*log(0/0) = 0
idx3 = find(P>0 & Q==0); % index for convention p*log(p/0) = Inf
% Calculation of the Kullback–Leibler divergence,
% by applying the three conventions described in "Elements of Information Theory..."
tmp = P .* log2( P./Q );
tmp(idx1) = 0; % convention 0*log(0/q) = 0
tmp(idx2) = 0; % convention 0*log(0/0) = 0
tmp(idx3) = Inf; % convention p*log(p/0) = Inf
KLD = sum(tmp)
Which leads to:
sum(Qtmp) =
1.00000000005
sum(Q) =
1
KLD =
0.247957353229104