I have deployed a model on a batch endpoint, and it works when i create the job by the GUI, selecting via wizard the input and output data locations.
I need to run it from notebook, in particular i've seen that the microsoft tutorial suggest to use the "invoke" method to call the batch endpoint, i do this way:
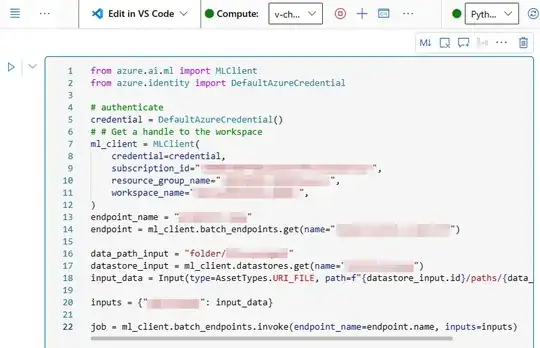
ml_client = MLClient(DefaultAzureCredential(), subscription_id, resource_group, workspace)
endpoint_name="endpoint-name"
endpoint = ml_client.batch_endpoints.get(name = "loaded-models-endpoint")
The credentials are correct, through the ml_client i'm able to retrieve the endpoint. I continue setting up the input object
data_path_input = "folder/file.parquet"
datastore_input = ml_client.datastores.get(name = "datastorename")
input_data = Input(type=AssetTypes.URI_FILE, path=f"{datastore_input.id}/paths/{data_path_input}")
print(input_data)
the result is
{'type': 'uri_folder', 'path': 'datastore_id_path.../paths/fodler/file.parquet'}
job = ml_client.batch_endpoints.invoke(
endpoint_name = endpoint.name,
inputs = {"deployement-name" : input_data}
)
ValidationException: Invalid input path
I tried not using the dictionary, but the simple input, due to the fact that i have only a single deployemnt on that endpoint:
job = ml_client.batch_endpoints.invoke(
endpoint_name = endpoint.name,
input = input_data
)
I also tried to provide directly the uri to the file:
job = ml_client.batch_endpoints.invoke(
endpoint_name = endpoint.name,
input = uri_to_file
)
In this case it raises:
JSONDecodeError: Expecting value: line 1 column 1 (char 0) During handling of the above exception, another exception occurred: Exception: BY_POLICY