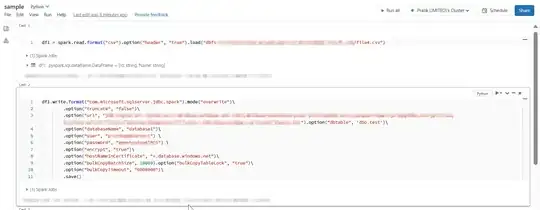
I am trying to write dataframe data into a table in Azure SQL from Databricks using pyspark. Table : dbo.test already exists in the database. I am able to read it before I execute below write operation.
testDf.write.format("com.microsoft.sqlserver.jdbc.spark").mode("overwrite")\
.option("truncate", "false")\
.option("url", azure_sql_url).option("dbtable", 'dbo.test')\
.option("databaseName", database_name)\
.option("user", username) \
.option("password", password) \
.option("encrypt", "true")\
.option("hostNameInCertificate", "*.database.windows.net")\
.option("bulkCopyBatchSize", 10000).option("bulkCopyTableLock", "true")\
.option("bulkCopyTimeout", "6000000")\
.save()
After executing this command the following error is returned:
java.lang.NoSuchMethodError: org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.schemaString(Lorg/apache/spark/sql/Dataset;Ljava/lang/String;Lscala/Option;)Ljava/lang/String;
Surprisingly, the dbo.test table gets deleted.
Can someone help me understand why this is happening. Same code works fine in another environment.