i am trying to merge multiple part file into single file. In staging folder, it itterating the all files, schema is same. part file we are converting .Tab files. Files are generating based on salesorgcode ex:7001 ,600,8002 every country having different salesorgcode but schema is same can anyone suggest. Note: files keeping blob container
Asked
Active
Viewed 155 times
1 Answers
0
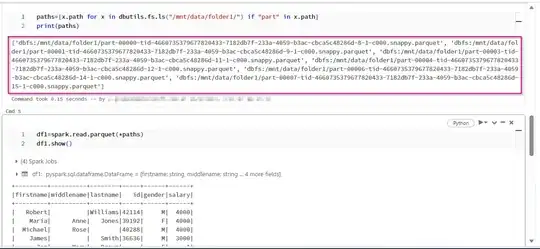
First mount the source container to databricks and store the parquet files which have "part" in the file name in a list.
Then, read it as pyspark dataframe. To get a single output file, convert it into pandas dataframe and write it to the output folder using mount point.
# Mount the source container and store the list of files
paths=[x.path for x in dbutils.fs.ls("/mnt/data/folder1/") if "part" in x.path]
df1=spark.read.parquet(*paths)
df1.show()
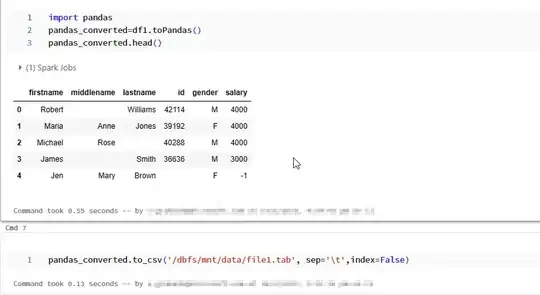
# convert pyspark dataframe to pandas datframe
import pandas
pandas_converted=df1.toPandas()
# write pandas dataframe to the .tab file in blob storage using mount point
pandas_converted.to_csv('/dbfs/mnt/data/file1.tab', sep='\t',index=False)
Add the header and seperator as per your requirement.
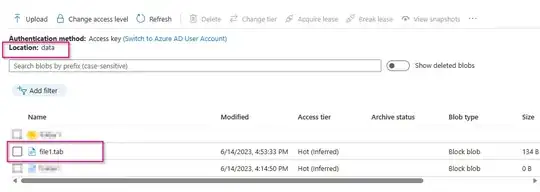
Output file:
Rakesh Govindula
- 5,257
- 1
- 2
- 11