you can see a different response from API
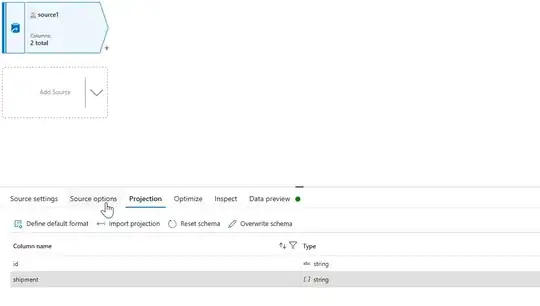
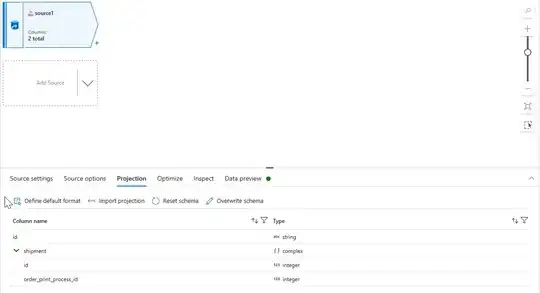
Explanation: In the above-shared screenshot, I compared two different files. On the left side is the data of web page no 1 while on the right side, I get the data of web page no 1080. You can see that on web page no 1 I am getting a shipment in array [ ] form which is empty, while on web page 1080 I am getting a shipment in object {} format. Furthermore, inside this object, I am getting an array [ ] of pd-option
This will help you to understand the array and object of shipment
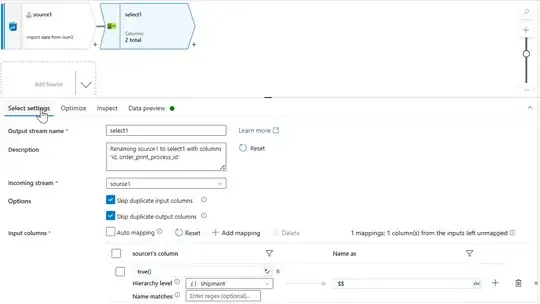
So my question is it necessary to have the same format of the file in ADF BECAUSE I want to transform 1700 files to flatten or not then how we can give different formats in Azure ADF to flatten the files?
{kind=link}
{kind=link}