I have a query which gives me the latest version of a delta table in the following format
(Query 1):
%sql
SELECT VERSION FROM (DESCRIBE HISTORY dbo.customers LIMIT 1)
This gives me output like this:

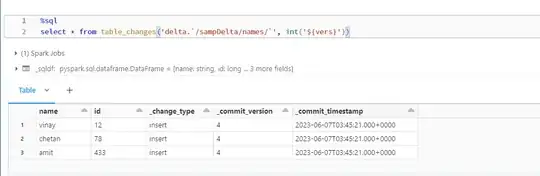
I have a query for table_changes which I'm using it in this way
(Query 2):
%sql
select * from table_changes('dbo.customers', 3)
It gives me the records of whatever changes were there in version 3 which is the latest version.
Now, when I am trying to do it in 1 query instead of 2, I attempted the following
(Query 3):
%sql
select * from table_changes('dbo.customers', SELECT VERSION FROM (DESCRIBE HISTORY dbo.customers LIMIT 1))
It gives me a syntax error.
I understand that (Query 1) is returning a table but I just want to use the value of the first row in the second argument of the table_changes function.
How do I use it or is there any better way to get the result in a single query?