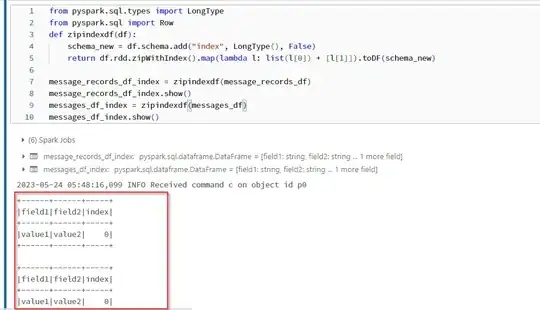
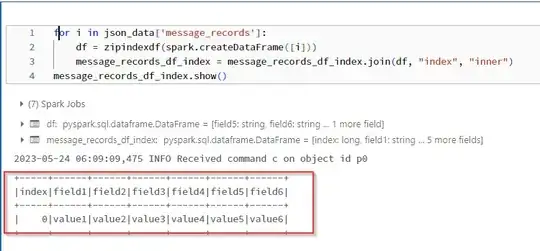
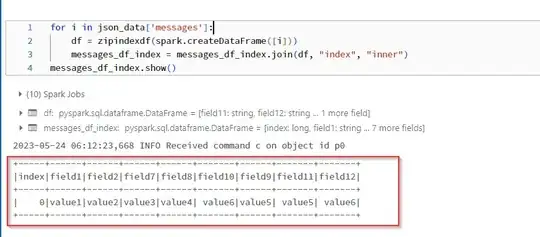
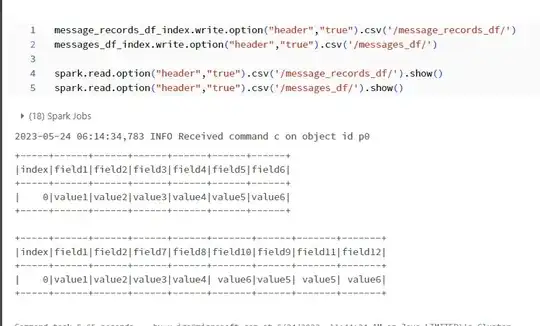
I have recieve a json file as input from the api here is the sample json.
json_data =
{
"field1": "value1",
"field2": "value2",
"message_records": [
{
"field3": "value3",
"field4": "value4"
},
{
"field5": "value5",
"field6": "value6"
}
],
"messages": [
{
"field7": "value3",
"field8": "value4"
},
{
"field9": "value5",
"field10": "value6"
},
{
"field11": "value5",
"field12": "value6"
}
]
}
how to flattern the json data into an individual rows using python and load the data into dataframe .here messages,message_records having nested arrays need to load into individual records. Convert the json file to pyspark dataframe
Here field1,field2 is common for message_records and messages i need to write the message_records data to a seperate file and messages data to a seperate file