Questions
Question 1: as the size of the database table gets larger how can I tune MySQL to increase the speed of the LOAD DATA INFILE call?
Question 2: would using a cluster of computers to load different csv files, improve the performance or kill it? (this is my bench-marking task for tomorrow using the load data and bulk inserts)
Goal
We are trying out different combinations of feature detectors and clustering parameters for image search, as a result we need to be able to build and big databases in a timely fashion.
Machine Info
The machine has 256 gig of ram and there are another 2 machines available with the same amount of ram if there is a way to improve the creation time by distributing the database?
Table Schema
the table schema looks like
+---------------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------------+------------------+------+-----+---------+----------------+
| match_index | int(10) unsigned | NO | PRI | NULL | |
| cluster_index | int(10) unsigned | NO | PRI | NULL | |
| id | int(11) | NO | PRI | NULL | auto_increment |
| tfidf | float | NO | | 0 | |
+---------------+------------------+------+-----+---------+----------------+Benchmarking so far
First step was to compare bulk inserts vs loading from a binary file into an empty table.
It took: 0:09:12.394571 to do 4,000 inserts with 5,000 rows per insert
It took: 0:03:11.368320 seconds to load 20,000,000 rows from a csv fileGiven the difference in performance I have gone with loading the data from a binary csv file, first I loaded binary files containing 100K, 1M, 20M, 200M rows using the call below.
LOAD DATA INFILE '/mnt/tests/data.csv' INTO TABLE test;I killed the 200M row binary file (~3GB csv file) load after 2 hours.
So I ran a script to create the table, and insert different numbers of rows from a binary file then drop the table, see the graph below.

It took about 7 seconds to insert 1M rows from the binary file. Next I decided to benchmark inserting 1M rows at a time to see if there was going to be a bottleneck at a particular database size. Once the Database hit approximately 59M rows the average insert time dropped to approximately 5,000/second

Setting the global key_buffer_size = 4294967296 improved the speeds slightly for inserting smaller binary files. The graph below shows the speeds for different numbers of rows
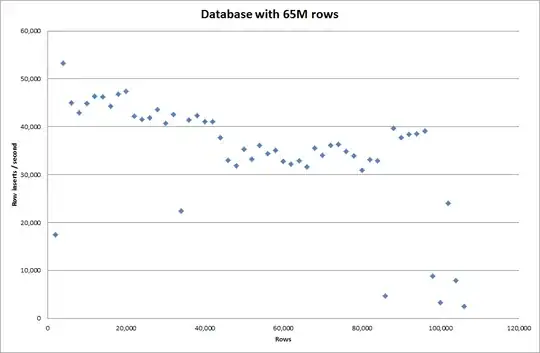
However for inserting 1M rows it didn't improve the performance.
rows: 1,000,000 time: 0:04:13.761428 inserts/sec: 3,940
vs for an empty database
rows: 1,000,000 time: 0:00:6.339295 inserts/sec: 315,492