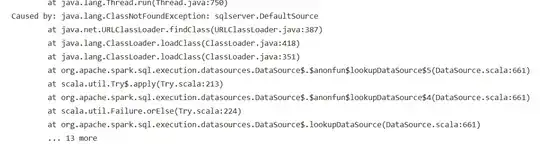
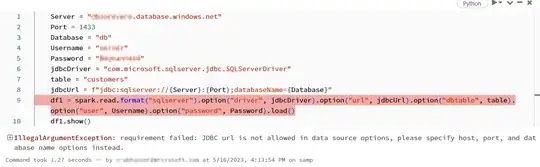
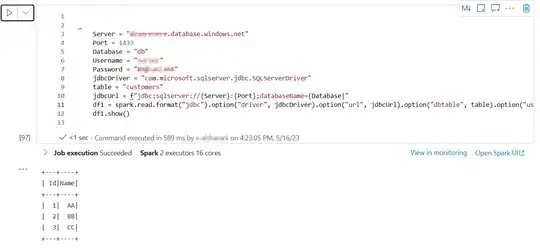
I'm trying to connect to a database from a pyspark Synapse analytics notebook using a jdbc driver. I'm having a Py4JJavaError when running my code but I can't see the full output of the error. The remaining rows of the error are hidden behind "... 27 more".
I tried to check the logs of the Spark pool but it's the same output with the remaining 27 rows hidden.
I tried also to use different options in the notebook like for example the magic command %tb or setting the SparkContext setLogLevel to ("DEBUG") and ("INFO") as well but I'm still having the same problem.
Thank you for your help.