My understanding is Parquet tables in Databricks do not maintain an explicit history of user activity.
And also similar to Parquet tables, external tables do not have built-in history tracking.
Here is the way you can track users using the log audit tables in databricks
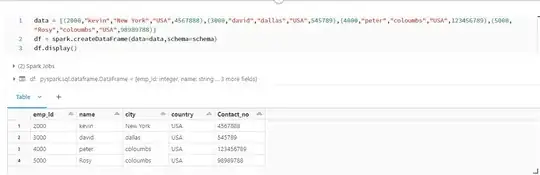
For example I have
from pyspark.sql.types import *
from pyspark.sql.functions import *
schema=StructType([StructField("emp_Id",IntegerType(),True), StructField("name",StringType(),True),StructField("city",StringType(),True),StructField("country",StringType(),True),StructField("Contact_no",IntegerType(),True)])
data = [(2000,"kevin","New York","USA",4567888),(3000,"david","dallas","USA",545789),(4000,"peter","coloumbs","USA",123456789),(5000,"Rosy","coloumbs","USA",98989788)]
df = spark.createDataFrame(data=data,schema=schema)
df.display()

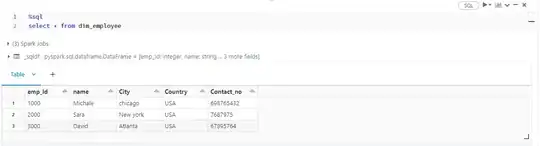
I have created a delta table which is the target location:
%sql
Create Or Replace TABLE dim_employee
(emp_Id INT,
name STRING,
City String,
Country String,
Contact_no INT
)
Using DELTA
LOCATION "/FileStore/Tables/delta_merge"
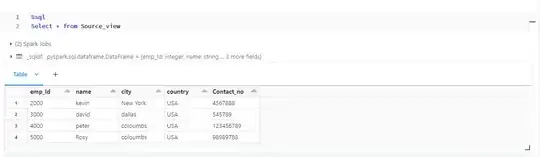
Creating a dataframe for the source:
df.createOrReplaceTempView("Source_view")
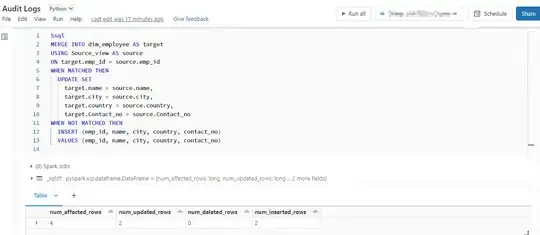
Using the Merge statement to (INSERT, UPDATE, DELETE) the source and target.
%sql
MERGE INTO dim_employee AS target
USING Source_view AS source
ON target.emp_Id = source.emp_id
WHEN MATCHED THEN
UPDATE SET
target.name = source.name,
target.city = source.city,
target.country = source.country,
target.Contact_no = source.Contact_no
WHEN NOT MATCHED THEN
INSERT (emp_id, name, city, country, contact_no)
VALUES (emp_id, name, city, country, contact_no)
Now creating an audit log table:
%sql
Create Table Audit_logs
(operation string,
updated_time timestamp,
user_name string,
notebook_name string,
numTargetRowsUpdated int,
numTargetRowsInserted int,
numTargetRowsDeleted int)
Create dataframe with lastoperation in delta table:
from delta.tables import *
delta.df= DeltaTable.forPath(spark,"/FileStore/Tables/delta_merge" )
lastOperationDF= delta.df.history()
The above statement get the last operation
display(lastOperationDF):
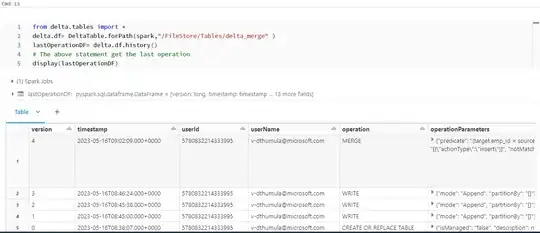
Leveraging the OperationParametres column for inserting the values into Audit_table. OperationParameters is string we will have to use the explode to flatten the value
Explode Df:
explode_DF =lastOperationDF.select(lastOperationDF.operation,explode(lastOperationDF.operationMetrics))
explode_DF_select = explode_DF.select(explode_DF.operation, explode_DF.key, explode_DF.value.cast('int'))
display(explode_DF_select)
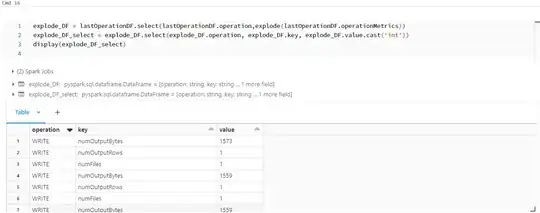
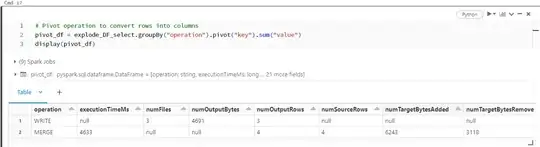
Pivot operation to convert rows into columns:
pivot_df = explode_DF_select.groupBy("operation").pivot("key").sum("value")
display(pivot_df)
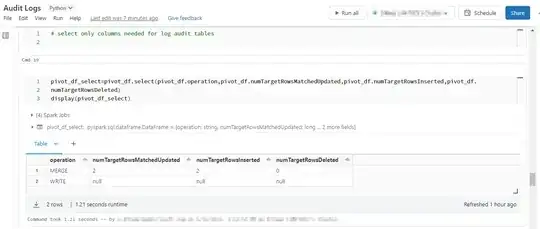
Select only columns needed for log audit tables:
pivot_df_select=pivot_df.select(pivot_df.operation,pivot_df.numTargetRowsMatchedUpdated,pivot_df.numTargetRowsInserted,pivot_df.
numTargetRowsDeleted)
display(pivot_df_select)
Adding notebook parameters such as username, notepath etc.:
from pyspark.sql.functions import lit, current_timestamp
audit_df = pivot_df_select.withColumn("user_name", lit(dbutils.notebook.entry_point.getDbutils().notebook().getContext().userName().get())) \
.withColumn("notebook_name", lit(dbutils.notebook.entry_point.getDbutils().notebook().getContext().notebookPath().get())) \
.withColumn("Updated_time", lit(current_timestamp()))
display(audit_df)
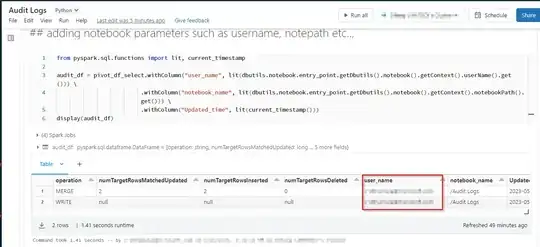
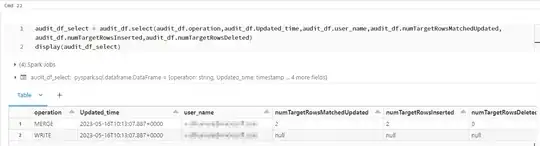
Rearranging the columns similar to audit table in SQL:
audit_df_select = audit_df.select(audit_df.operation,audit_df.Updated_time,audit_df.user_name,audit_df.numTargetRowsMatchedUpdated,audit_df.numTargetRowsInserted,audit_df.numTargetRowsDeleted)
display(audit_df_select)
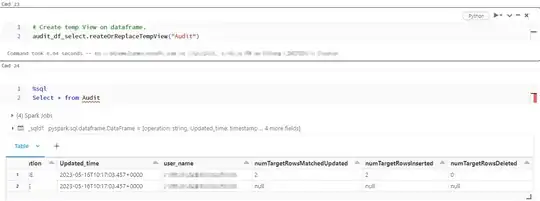
Create temp view on dataframe:
audit_df_select.createOrReplaceTempView("Audit")
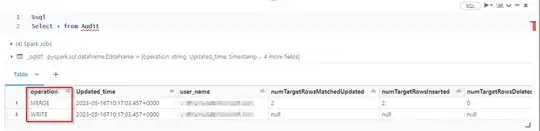
Inserting the rows from Audit into Audit_logs:

Regarding the better way to cleanup databricks data is
Handle missing values, Remove duplicates, Convert data types,
Filter and transform data.
These above data transformation should help you better in cleaning the data in databricks.