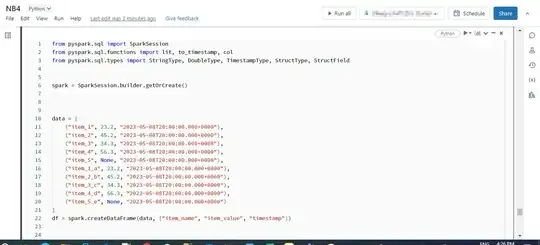
I have a list and a table like below and what I need to do is to go through values in the item name column in the table and find the item name that is available in a list but missing from the table if there is any. then I need to insert that missing item_name into the table with null value for the item value column and the same timestamp as others for the timestamp column.
list_of_tags = ["item_1", "item_2", "item_3", "item_4", "item_5", "item_1_a", "item_1_b", "item_1_c", "item_1_d", "item_1_e" ]
|item_name | item_value | timestamp |
|:------- |:------:| ----------------------------:|
| item_1 | 23.2 | 2023-05-08T20:00:00.000+0000 |
| item_2 | 45.2 | 2023-05-08T20:00:00.000+0000 |
| item_3 | 34.3 | 2023-05-08T20:00:00.000+0000 |
| item_4 | 56.3 | 2023-05-08T20:00:00.000+0000 |
| item_1_a | 23.2 | 2023-05-08T20:00:00.000+0000 |
| item_2_b | 45.2 | 2023-05-08T20:00:00.000+0000 |
| item_3_c | 34.3 | 2023-05-08T20:00:00.000+0000 |
| item_4_d | 56.3 | 2023-05-08T20:00:00.000+0000 |
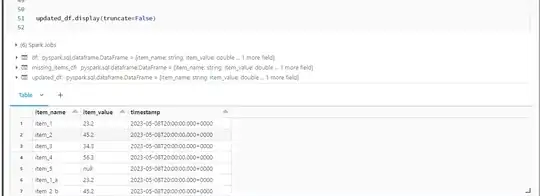
the outcome I want is
|item_name | item_value | timestamp |
|:------ |:------------:| ----------------------------:|
| item_1 | 23.2 | 2023-05-08T20:00:00.000+0000 |
| item_2 | 45.2 | 2023-05-08T20:00:00.000+0000 |
| item_3 | 34.3 | 2023-05-08T20:00:00.000+0000 |
| item_4 | 56.3 | 2023-05-08T20:00:00.000+0000 |
| item_4 | 56.3 | 2023-05-08T20:00:00.000+0000 |
| item_5 | null | 2023-05-08T20:00:00.000+0000 |
| item_1_a | 23.2 | 2023-05-08T20:00:00.000+0000 |
| item_2_b | 45.2 | 2023-05-08T20:00:00.000+0000 |
| item_3_c | 34.3 | 2023-05-08T20:00:00.000+0000 |
| item_4_d | 56.3 | 2023-05-08T20:00:00.000+0000 |
| item_5_e | null | 2023-05-08T20:00:00.000+0000 |
How can I do this using Pyspark?
Any help is greatly appreciated