My understanding is handling bad data in Azure Data Lake Gen2
Azure Data Factory(ETL) to copy data from source systems into your data lake,
And configure a data validation step in your pipeline to identify and flag bad data before it is ingested into the lake.
You can use tools like Azure Databricks as you said you are having the Bigdata Databricks would be a good option for Cleanising,Transforming.
In azure Data Lake Storage Gen2 the feature of hierarchical namespace to store bad data in a separate folder from good data.
This approach allows you to keep bad data separate from the rest of your data, and makes it easier to locate and delete it when necessary.
For example In DataBricks we have Below Techniques will do Error Handling and write them in ADLS Gen2
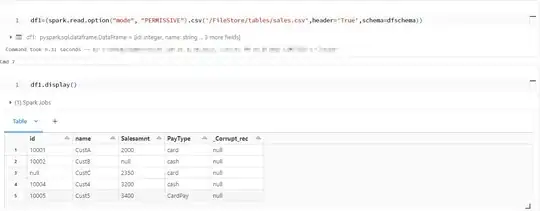
• PERMISSIVE: replaces null value to the corrupt record and adds an addition column _corrupt_record with the corrupt row value.
ex:df2=spark.read.option("mode","PERMISSIVE").csv("/FileStore/tables/new_insurance_data.csv",header=True,schema=myschema2)
• DROPMALFORMED: drop the corrupt records from the dataframe.
ex:df3=spark.read.option("mode","DROPMALFORMED").csv("/FileStore/tables/new_insurance_data.csv",header=True,schema=myschema2)
• FAILFAST: Fails the command if any corrupt records are present in the data.
ex:df4=spark.read.option("mode","FAILFAST").csv("/FileStore/tables/new_insurance_data.csv",header=True,schema=myschema2)
• badRecordsPath: Drops the corrupt record from the dataframe and stores the corrupt records to the specified path.
ex:df5=spark.read.option("badRecordsPath","/demo/").csv("/FileStore/tables/new_insurance_data.csv",header=True,schema=myschema2)
I have performed these above steps in the databricks
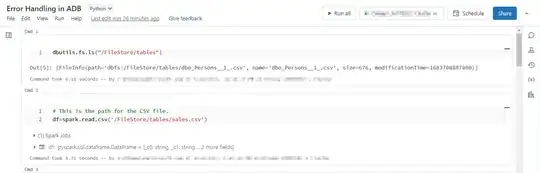
To check the Files in the databricks
dbutils.fs.ls("/FileStore/tables")
. This is the path for the CSV file.
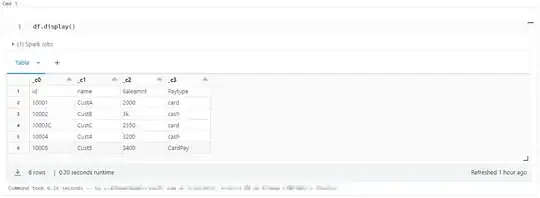
df=spark.read.csv('/FileStore/tables/sales.csv')
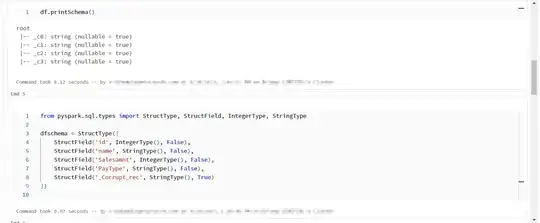
from pyspark.sql.types import StructType, StructField, IntegerType, StringType
dfschema = StructType([
StructField('id', IntegerType(), False),
StructField('name', StringType(), False),
StructField('Salesamnt', IntegerType(), False),
StructField('PayType', StringType(), False),
StructField('_Corrupt_rec', StringType(), True)
])
Reconsructing the Schema.
1st Method.
df1=(spark.read.option("mode", "PERMISSIVE").csv('/FileStore/tables/sales.csv',header='True',schema=dfschema))
2nd Method.
. DROPMALFORMED will drop the records
df2=(spark.read.option("mode", "DROPMALFORMED").csv('/FileStore/tables/sales.csv',header='True',schema=dfschema))

3rd method.
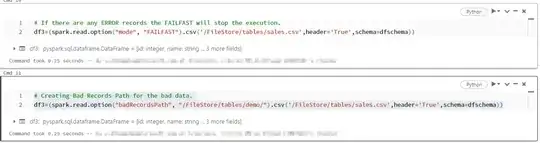
.If there are any ERROR records the FAILFAST will stop the execution.
df3=(spark.read.option("mode", "FAILFAST").csv('/FileStore/tables/sales.csv',header='True',schema=dfschema))
. Creating Bad Records Path for the bad data.
df3=(spark.read.option("badRecordsPath", "/FileStore/tables/demo/").csv('/FileStore/tables/sales.csv',header='True',schema=dfschema))
Once the data is in transformed then it wrtten in to ADLS GEN2 and from there it will moved to synapse using ADF.
And also would Like to let you know as you asked specifically in Azure synapse as per my experience I have handled the big data transformation and Clensing the data and writing the Curated data into Azure synpase(target).