I'm working with data flows in data factory to create a dynamic data flow which has parameterized source/sink/surrogate key names to reuse across many files and accomplishes the following tasks:
- Join source parquet to existing delta destination to find new/updated records.
- Insert new rows with a numeric surrogate key
- compare hashes between source and existing destination and determine if record is different
- Update existing rows that that have a difference in the record hash
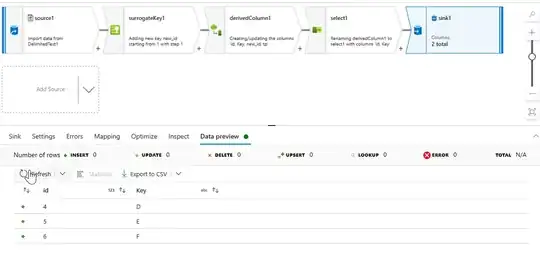
I am able to get data throughout the flow, but I am running into an issue during the sinks. It seems that I am unable to insert records from my incoming stream to the sink because of a schema mismatch. sample schema below:
Source stream final schema where I've highlighted the columns that I don't want in my delta table:

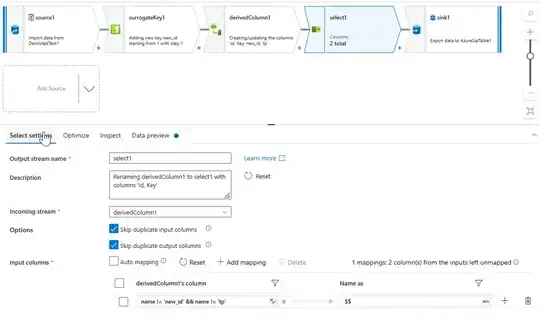
I am aware of the mismatch between source/sink. It's caused by additional work that goes into creating surrogate keys and determining if records have changed.
When I turn off auto-mapping I'm able to map columns and drop columns without any issues but then I lose the ability to make this flow dynamic. Are there settings in the sink that will allow auto-mapping to drop columns from the source that don't match destination?
Things I've tried:
Unchecking "Allow schema drift". To me this makes sense, I don't want my destination schema to drift, but when I uncheck this, the auto-mapping doesn't seem to work and gives me the error: "Error at Sink 'sink1': The result has 0 output columns. Please ensure at least one column is mapped"
Checking "Allow schema drift". Checking this makes the automapper work but causes the error "Job failed due to reason: at Sink 'sink1': A schema mismatch detected when writing to the Delta table"
Now, I can also enable mergeSchema but then I will be writing the 5 columns I don't want into my delta table. Is there a way to get my sink to work such that automapping will map to columns it finds and drop columns it can't find so that I don't have to write a bunch of transient columns to my table?