as shown in the provided confusion matrix, the model is underfitting the data by predicting label 2 for all instances in the training set.

Probably this is also happening to the validation set and the reason why the validation accuracy is higher in this case is because the proportion of label-2 instances on validation set is higher.
It turns out that the chosen set of hyperparameters stink the model in some local minima over the cost function surface. Below is an illustration of the cost function surface in case your are not familiar with this concept already:
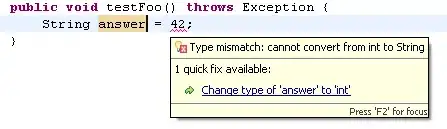
Since an underfitted model is useless, you need to explore some options for fix your model training.
Unfortunately, there is no deterministic path here. However, there are some common recommendations, especially for the case of underfitted models:
check the data: if the data cannot express a relation between the inputs and outputs you need to fix it (by adding features, cleaning or adding data, etc). Although I don't think that this is the cause of your particular problem, in general we also check the data when we get an underfitting.
Check the model: underfitting sometimes occurs because of the model capacity is low. Trying a bigger model (more trainable parameters) can solve the issue. Be careful and add parameters slowly. A really bigger model can cause your model to overfit. The best approach is starting with a small model and increasing it until you don't achieve the desired performance.
Try different optimizers: if you are using a ML library like Pytorch or Tensorflow, it is easy to change the training optimizer such as Adam, RMSProp, SGD, etc... Sometimes, Adam provides the fastest result, sometimes doesn't.
Tune the hyperparameters: Here we can play with several parameters. Learning rate and batch size are very tight correlated. A small Batch size usually requires a small learning rate. One very important and often forgot hyperparameter is the weight initialization. Frequently, you can avoid the local minima just by choosing different weight initializers.
Dealing with under and overfitting is a common scenario in model training. Sometimes, we can take a lot of time before realize where the problem is (initialization, learning rate, model size, etc). I think that a deep discussion about the choice of hyperparameters is beyond the scope of this answer. If you have an specific question about some of them, does not hesitate to ask.
A last word: using only accuracy for evaluate models performance is dangerous. As your example shows, the first model achieved a moderate performance (54%) despite it is totally unusable. To get more insightful feedback, use other more suitable metrics. Tow I would like to recommend for your problem are precision and recall:
Check here if you don't know what are local/global minima.
Check here if you don't know what is underfitting.





