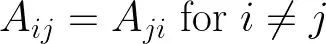I am trying to speed up my calculations and I am not sure, how to best use .into_par_iter() or some of the Zip:: options from the ndarray crate in order to "correctly" parallelize the computation to speed up things.
I have tried 2 ways, but I think due to my understanding of Mutex the whole Array gets "locked", which just creates more overhead and the calculations are slower than before.
- example:
//* Step 2.1: Calculate the overlap matrix S
let S_matr_tmp = Array2::<f64>::zeros((n, n));
let S_matr_mutex = Mutex::new(S_matr_tmp);
(0..n).into_par_iter().for_each(|i| {
(0..=i).into_par_iter().for_each(|j| {
let mut s = S_matr_mutex.lock().unwrap();
if i == j {
s[(i, j)] = 1.0;
// s = 1.0;
} else {
s[(i, j)] = calc_overlap_int_cgto(
&self.mol.wfn_total.basis_set_total.basis_set_cgtos[i],
&self.mol.wfn_total.basis_set_total.basis_set_cgtos[j],
);
s[(j, i)] = s[(i, j)];
}
})
});
self.mol.wfn_total.HF_Matrices.S_matr = S_matr_mutex.into_inner().unwrap();
- example:
let D_matr_mutex = Mutex::new(Array2::<f64>::zeros((no_cgtos, no_cgtos)));
//* D^0 matrix */
//* Trying to parallelize it */
Zip::indexed(C_matr_AO_basis.axis_iter(Axis(0))).par_for_each(|mu, row1| {
Zip::indexed(C_matr_AO_basis.outer_iter()).par_for_each(|nu, row2| {
let mut d = D_matr_mutex.lock().unwrap();
let slice1 = row1.slice(s![..no_occ_orb]);
let slice2 = row2.slice(s![..no_occ_orb]);
d[(mu, nu)] = slice1.dot(&slice2);
});
});
let mut D_matr = D_matr_mutex.into_inner().unwrap();
- example (most important code to parallelize):
let F_matr_mutex = Mutex::new(F_matr);
(0..no_cgtos).into_par_iter().for_each(|mu| {
(0..no_cgtos).into_par_iter().for_each(|nu| {
(0..no_cgtos).into_par_iter().for_each(|lambda| {
(0..no_cgtos).into_par_iter().for_each(|sigma| {
let mu_nu_lambda_sigma =
calc_ijkl_idx(mu + 1, nu + 1, lambda + 1, sigma + 1);
let mu_lambda_nu_sigma =
calc_ijkl_idx(mu + 1, lambda + 1, nu + 1, sigma + 1);
let mut f = F_matr_mutex.lock().unwrap();
f[(mu, nu)] += D_matr[(lambda, sigma)]
* (2.0
* self.mol.wfn_total.HF_Matrices.ERI_arr1[mu_nu_lambda_sigma]
- self.mol.wfn_total.HF_Matrices.ERI_arr1[mu_lambda_nu_sigma]);
});
});
});
});
let F_matr = F_matr_mutex.into_inner().unwrap();
Any help on how to parallelize the code "correctly" and more information on how to use Mutex better would be appreciated.