I read csv file form my storage into a dataframe.
Here is my file:

I created new column called 'Unit' by splitting consumed column;
split_cols = pyspark.sql.functions.split(df['Consumed'], ' ')
df = df.withColumn('Unit', split_cols.getItem(1))
df = df.withColumn('Unit', when(df['Unit'] == 'KB', 'GB').otherwise(df['Unit']))
I converted kb value into GB of consumed value by using below code:
df = df.withColumn("Consumed",
when(df["Consumed"].contains("GB"),
round(regexp_extract(df["Consumed"], r"(\d+\.?\d*)", 1).cast("double"), 2)
)
.when(df["Consumed"].contains("KB"),
round(regexp_extract(df["Consumed"], r"(\d+\.?\d*)", 1).cast("double")/1000000, 5)
)
.otherwise(0)
)
When I try with above one, I am getting 670 kb value as 6.7E-4 i.e., it is converting as scientific notification.
So, I formatted it by using below command
df = df.withColumn("Consumed", when(col("Consumed") == 6.7E-4, format_number(col("Consumed"),5)).otherwise(col("Consumed")))
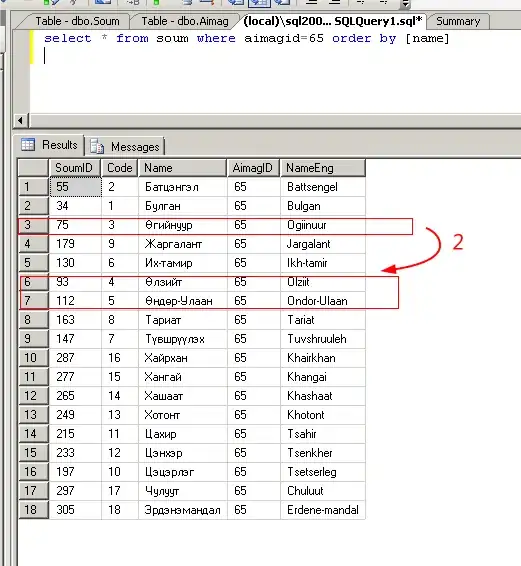
And selected columns in below format
df = df.select('ID', 'Consumed', 'Unit', 'Total')
Output:
!! IMPORTANT: The problem I have is that it all should be done in the same file (no new files have to be created)
Mount the path using below procedure:
Create linked service of path and created mount using below code:
mssparkutils.fs.mount(
"abfss://<container>@<storageacc>.dfs.core.windows.net",
"<mount container>",
{"linkedService":"AzureDataLakeStorage1"}
)

jobid=mssparkutils.env.getJobId()
path='/synfs/'+jobid+'/<mount container>/<filename>.csv'
I overwrite the updated dataframe into filename using below code:
df.toPandas().to_csv(path,index = False)
Updated file: