I am trying to wrangle/reorganize some multi-level grouped data from a .TXT source. Here is a generic version of my problem/question:
6x5 spreadsheet snip: three category indicators
(1 class, 3 groups (A,B,C), 2 levels (1,2)), two variables (var1, var2), twelve simulated datapoints)
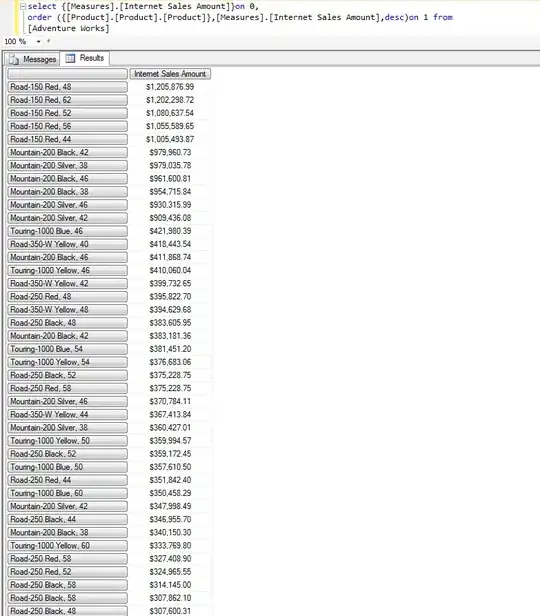
I am trying to reorganize it into: one record with twelve variables, as simplified below:
1x13 spreadsheet snip: one class, twelve variables (vara11,vara12,vara21,vara22,varb11,varb12,varb21,varb22,varc11,varc12,varc21,varc22)
The following prior exchanges seem to be relevant, but I am not (as yet) an adept-enough R-user to make good sense of them. If I grasped how to "create" the scenario within R, I would understand how to "undo" it. I am stuck.
Multi-level grouped data.frame How to summarise and subset multi-level grouped dataframe in dplyr and R
RowGroup Is there a way to make Multi - Level row grouping table in R DT pacakge
Help would be greatly appreciated.