I have a csv file with the column names in the first row. Unfortunately some of the fields have square brackets and spaces in them. Synapse is failing to load with this error:
AnalysisException: Attribute name "xxxxx [xxxxxxxx]" contains invalid character(s) among " ,;{}()\n\t=". Please use alias to rename it.
I have looked at spark-dataframe-column-naming-conventions-restrictions which provides some advice on how to restate the column names, but the data is already in a dataframe.
I would appreciate some recommendations on how to approach this issue in pyspark
Thanks
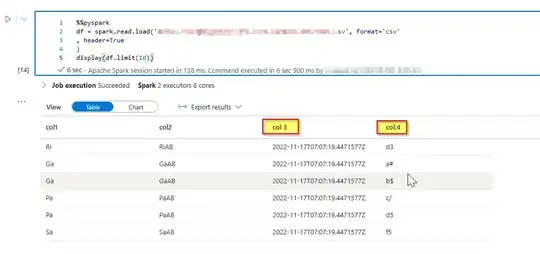 img:1 sample input dataframe
img:1 sample input dataframe img:2 Dataframe with Transformed column names.
img:2 Dataframe with Transformed column names.