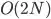I am trying to use regex to extract sentences containing specific words, and sentences before and next to them. My code works, but it takes 20 seconds for each txt and I have about a million txt files. Is it possible to get the same result in less time? Any other relalted suggestions are also welcome. Thanks!
My current thought is to extract paragraphs containing these target words first, then use nltk to tokenize target paragraphs and extract the target sentences and sentences before and next them.
Here is my demo:
import re, nltk
txt = '''There is widespread agreement that screening for breast cancer, when combined with appropriate follow-up, will reduce mortality from the disease. How we measure response to treatment is called the 5-year survival rate, or the percentage of people who live 5 years after being diagnosed with cancer. According to information provided by National Cancer Institute, Cancer stage at diagnosis, which refers to extent of a cancer in the body, determines treatment options and has a strong influence on the length of survival. In general, if the cancer is found only in the part of the body where it started it is localized (sometimes referred to as stage 1). If it has spread to a different part of the body, the stage is regional or distant . The earlier female breast cancer is caught, the better chance a person has of surviving five years after being diagnosed. For female breast cancer, 62.5 are diagnosed at the local stage. The 5-year survival for localized female breast cancer is 98.8 . It decreases from 98.8 to 85.5 after the cancer has spread to the lymph nodes (stage 2), and to 27.4
(stage 4) after it has spread to other organs such as the lung, liver or brain. A major problem with current detection methods is that studies have shown that mammography does not detect 10 -20 of breast cancers that are detected by physical exam alone, which may be attributed to a falsely negative mammogram.
Breast cancer screening is generally recommended as a routine part of preventive healthcare for women over the age of 20 (approximately 90 million in the United States). Besides skin cancer, breast cancer is the most commonly diagnosed cancer among U.S. women. For these women, the American Cancer Society (ACS) has published guidelines for breast cancer screening including: (i) monthly breast self-examinations for all women over the age of 20; (ii) a clinical breast exam (CBE) every three years for women in their 20s and 30s; (iii) a baseline mammogram for women by the age of 40; and (iv) an annual mammogram for women age 40 or older (according to the American College of Radiology). Unfortunately, the U.S. Preventive Task Force Guidelines have stirred confusion by recommending biennial screening mammography for women ages 50-74.
Each year, approximately eight million women in the United States require diagnostic testing for breast cancer due to a physical symptom, such as a palpable lesion, pain or nipple discharge, discovered through self or physical examination (approximately seven million) or a non-palpable lesion detected by screening x-ray mammography
(approximately one million). Once a physician has identified a suspicious lesion in a woman's breast, the physician may recommend further diagnostic procedures, including a diagnostic x-ray mammography, an ultrasound study, a magnetic resonance imaging procedure, or a minimally invasive procedure such as fine needle aspiration or large core needle biopsy. In each case, the potential benefits of additional diagnostic testing must be balanced against the costs, risks and discomfort to the patient associated with undergoing the additional procedures.
'''
target_words = ['risks', 'discomfort', 'surviving', 'risking', 'risks', 'risky']
pattern = r'.*\b(?='+'|'.join(target_words) + r')\b.*'
target_paras = re.findall(pattern, txt, re.IGNORECASE)
# Function to extract sentences containing any target word and its neighbor sentences
def UncertaintySentences (paragraph):
sent_token = nltk.tokenize.sent_tokenize(paragraph)
keepsents = []
for i, sentence in enumerate(sent_token):
# sentences contain any target word
if re.search(pattern, sentence, re.IGNORECASE) != None:
try:
if i==0: # first sentence in a para, keep it and the one next to it
keepsents.extend([sent_token[i], sent_token[i+1]])
elif i!=len(sent_token)-1: # sentence in the middle, keep it ant the ones before and next to it
keepsents.extend([sent_token[i-1], sent_token[i], sent_token[i+1]])
else: # last sentence, keep it and the one before it
keepsents.extend([sent_token[i-1], sent_token[i]])
except: # para with only one sentence
keepsents = sent_token
# drop duplicate sentences
del_dup = []
[del_dup.append(x) for x in keepsents if x not in del_dup]
return(del_dup)
for para in target_paras:
uncertn_sents = UncertaintySentences(para)
print(uncertn_sents)
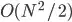 to
to