Please help me with copying data from Google BigQuery to Azure Data Lake Storage Gen2 with Serverless SQL Pool.
I am using Azure Synapse's Copy data pipeline. The issue is I cannot figure out how to handle source table from the BigQuery with hierarchical schema. This result in missing columns and inaccurate datetime value at the sink.
The source is a Google BigQuery table, it is made of Google Cloud Billing export of a project's standard usage cost. The source table's schema is hierarchical with nested columns, such as service.id; service.description; sku.id; sku.description; Project.labels.key; Project.labels.value, etc.
When I click on Preview data from the Source tab of the Copy data pipeline, it only gives me the top of the column hierarchy, for example: It would only show the column name of [service] and with value of {\v":{"f":[{"v":"[service.id]"},{"v":"[service.descrpition]"}]}} image description: Source with nested columns result in issues with Synapse Copy Data Pipline
I have tried to configure the Copy Pipline with the following:
Source Tab:
Use query - I think the solution lays in here, but I cannot figure out the syntax of selecting the proper columns. I watched a Youtube video from TechBrothersIT How to Pass Parameters to SQL query in Azure Data Factory - ADF Tutorial 2021, but still unable to do it.
Sink Tab:
1.Sink dataset in various format of csv, json and parquet - with csv and parquet getting similar result, and json format failed
2.Sink dataset to Azure SQL Database - failed because it is not supported with Serverless SQL Pool
3.Mapping Tab: note: edited on Jan22 with screenshot to show issue.
- Tried with Import schemas, with Sink Tab copy behavior of
None, Flatten Hierarchy and Preserve Hierarchy, but still unable to get source column to be recognized as Hierarchical. Unable to get the Collection reference nor the Advanced Editor configurations to show up. Ref: Screenshot of Source columns not detected as Hierarchical MS Doc on Schema and data type mapping in copy activity
I have also tried with the Data flow pipeline, but it does not support Google BigQueryData Flow Pipe Source do not support BigQuery yet
Here are the steps to reproduce / get to my situation:
- Register Google cloud, setup billing export (of standard usage cost) to BigQuery.
- At Azure Synapse Analytics, create a Linked service with user authentication. Please follow Data Tech's Youtube video "Google BigQuery connection (or linked service) in Azure Synapse analytics"
- At Azure Synapse Analytics, Integrate, click on the "+" sign -> Copy Data Tool
I believe the answer is at the Source tab with Query and Functions, please help me figure this out, or point me to the right direction.
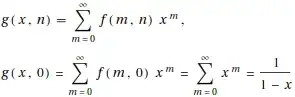
Looking forward to your input. Thanks in advance!
 img:1 nested table
img:1 nested table img:2 sample data of nested table
img:2 sample data of nested table img:3 flattened table.
img:3 flattened table. img:4 Source settings of copy activity.
img:4 Source settings of copy activity.{kind=link}
{kind=link}
{kind=link}