I am looking to do scraping of the website https://www.bananatic.com/es/forum/games/
and extract the tags "name", "views" and "replies". I have a big problem to get the non-empty content of the "name" tag. Can you help me? I need to save only the elements that do have text.
This is my code, I have three variables:
- per save what is inside the replies.
- pir save what is inside the views
- res saves what is inside the names.
Each array should contain only the elements that they have. something but in the names the writings [" "] are saved and I want them not to be saved in my array.
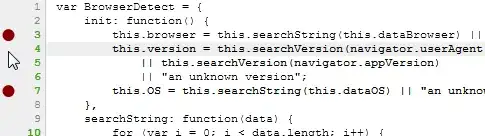
require 'nokogiri'
require 'open-uri'
require 'pp'
require 'csv'
unless File.readable?('data.html')
url = 'https://www.bananatic.com/de/forum/games/'
data = URI.open(url).read
File.open('data.html', 'wb') { |f| f << data }
end
data = File.read('data.html')
document = Nokogiri::HTML(data)
per = document.xpath('//div[@class="replies"]/text()[string-length(normalize-space(.)) > 0]')
.map { |node| node.to_s[/\d+/] }
p per
pir = document.xpath('//div[@class="views"]/text()[string-length(normalize-space(.)) > 0]')
.map { |node| node.to_s[/\w+/] }
p pir
links2 = document.css('.topics ul li div')
res = links2.map do |lk|
name = lk.css('.name p a').inner_text
[name]
end
p res
To fix it I have added a regular expression, however I have failed in the attempt.
I just replace .inner_textwith .to_s[/\w+/], but I don't get it.
Now I have an array with null values and some letters "a" that I don't know where they appear.