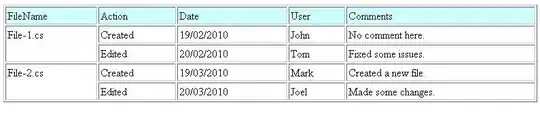
I am attempting to carry the following merge statement with PySpark on the table below (please note, this is my first attempt at creating a table on Stack Overflow using HTML snippet, so I have it shows the table - I think you have to click on RUN CODE SNIPPET to view the table).
try:
#Perform a merge into the existing table
if allowDuplicates == "true":
(deltadf.alias("t")
.merge(
partdf.alias("s"),
f"s.primary_key_hash = t.primary_key_hash")
.whenNotMatchedInsertAll()
.execute()
)
else:
(deltadf.alias("t")
.merge(
partdf.alias("s"),
"s.primary_key_hash = t.primary_key_hash")
.whenMatchedUpdateAll("s.change_key_hash <> t.change_key_hash")
.whenNotMatchedInsertAll().
execute()
)
However, I keep on getting the error:
Cannot perform Merge as multiple source rows matched and attempted to modify the same target row in the Delta table in possibly conflicting ways. By SQL semantics of Merge, when multiple source rows match on the same target row, the result may be ambiguous as it is unclear which source row should be used to update or delete the matching target row.
Can someone take a look at my code and let me know why I keep on getting the error please.
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=Windows-1252" />
<title>Export Data</title>
<style type="text/css">
.h {
color: Black;
font-family: Tahoma;
font-size: 8pt;
}
table {
border-collapse: collapse;
border-width: 1px;
border-style: solid;
border-color: Silver;
padding: 3px;
}
td {
border-width: 1px;
border-style: solid;
border-color: Silver;
padding: 3px;
}
.rh {
background-color: White;
vertical-align: Top;
color: Black;
font-family: Tahoma;
font-size: 8pt;
text-align: Left;
}
.rt {
background-color: White;
vertical-align: Top;
color: Black;
font-family: Tahoma;
font-size: 8pt;
text-align: Left;
}
</style>
</head>
<bodybgColor=White>
<p class="h"></p>
<table cellspacing="0">
<tr class="rh">
<td>Id</td>
<td>SinkCreatedOn</td>
<td>SinkModifiedOn</td>
</tr>
<tr class="rt">
<td>AC28CA8A-80B6-EC11-983F-0022480078D3</td>
<td>15/12/2022 14:02:51</td>
<td>15/12/2022 14:02:51</td>
</tr>
<tr class="rt">
<td>AC28CA8A-80B6-EC11-983F-0022480078D3</td>
<td>16/12/2022 18:30:59</td>
<td>16/12/2022 18:30:59</td>
</tr>
<tr class="rt">
<td>AC28CA8A-80B6-EC11-983F-0022480078D3</td>
<td>16/12/2022 18:55:04</td>
<td>16/12/2022 18:55:04</td>
</tr>
<tr class="rt">
<td>AC28CA8A-80B6-EC11-983F-0022480078D3</td>
<td>20/12/2022 16:26:45</td>
<td>20/12/2022 16:26:45</td>
</tr>
<tr class="rt">
<td>AC28CA8A-80B6-EC11-983F-0022480078D3</td>
<td>22/12/2022 17:27:45</td>
<td>22/12/2022 17:27:45</td>
</tr>
<tr class="rt">
<td>AC28CA8A-80B6-EC11-983F-0022480078D3</td>
<td>22/12/2022 17:57:48</td>
<td>22/12/2022 17:57:48</td>
</tr>
</table>
<p class="h"></p>
</body>
</html>I am going to use the following dedup code as suggested:
from pyspark.sql.window import Window
from pyspark.sql.functions import row_number
df2 = partdf.withColumn("rn", row_number().over(Window.partitionBy("primary_key_hash").orderBy("Id")))
df3 = df2.filter("rn = 1").drop("rn")
display(df3)
In order to make the code work with my merge statement would it need to look like the following:
try:
#Perform a merge into the existing table
if allowDuplicates == "true":
(deltadf.alias("t")
.merge(
df3.alias("s"),
f"s.primary_key_hash = t.primary_key_hash")
.whenNotMatchedInsertAll()
.execute()
)
else:
(deltadf.alias("t")
.merge(
df3.alias("s"),
"s.primary_key_hash = t.primary_key_hash")
.whenMatchedUpdateAll("s.change_key_hash <> t.change_key_hash")
.whenNotMatchedInsertAll().
execute()
)
You will notice the I have removed the partdf from the merge statement and replace it with df3