Trying out
https://delta.io/blog/2022-05-18-multi-cluster-writes-to-delta-lake-storage-in-s3/ https://docs.google.com/document/d/1Gs4ZsTH19lMxth4BSdwlWjUNR-XhKHicDvBjd2RqNd8/edit#
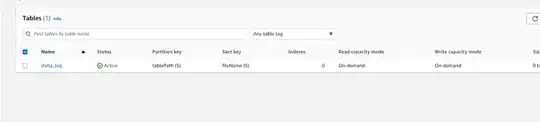
DynamoDB tables
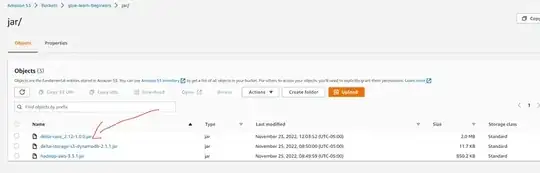
jar files
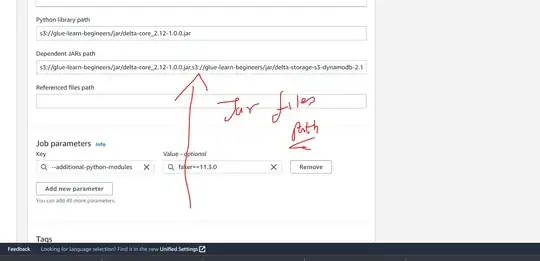
jar file path provided
When i run my code i dont see any messages in the dynamodb table here is code
try:
import os
import sys
import pyspark
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, asc, desc
from pyspark.sql.functions import *
from delta.tables import *
from delta.tables import DeltaTable
print("All modules are loaded .....")
except Exception as e:
print("Some modules are missing {} ".format(e))
class DeltaLakeHelper(object):
"""
Delta Lakes Python helper class that aids in basic operations such as inserting, updating, deleting, merging, removing older files and versions, and generating Athena manifest files.
"""
def __init__(self, delta_lake_path: str):
self.spark = self.__create_spark_session()
self.delta_lake_path = delta_lake_path
self.delta_df = None
def generate_manifest_files(self):
"""
Generates Manifest file for Athena
:return: Bool
"""
self.delta_df.generate("symlink_format_manifest")
return True
def __generate_delta_df(self):
try:
if self.delta_df is None:
self.delta_df = DeltaTable.forPath(self.spark, self.delta_lake_path)
except Exception as e:
pass
def compact_table(self, num_of_files=10):
"""
Converts smaller parquert files into larger Files
:param num_of_files: Int
:return: Bool
"""
df_read = self.spark.read.format("delta") \
.load(self.delta_lake_path) \
.repartition(num_of_files) \
.write.option("dataChange", "false") \
.format("delta") \
.mode("overwrite") \
.save(self.delta_lake_path)
return True
def delete_older_files_versions(self):
"""
Deletes Older Version and calls vacuum(0)
:return: Bool
"""
self.__generate_delta_df()
self.delta_df.vacuum(0)
return True
def insert_overwrite_records_delta_lake(self, spark_df, max_record_per_file='10000'):
"""
Inserts into Delta Lake
:param spark_df: Pyspark Dataframe
:param max_record_per_file: str ie max_record_per_file= "10000"
:return:Bool
"""
spark_df.write.format("delta") \
.mode("overwrite") \
.option("maxRecordsPerFile", max_record_per_file) \
.save(self.delta_lake_path)
return True
def append_records_delta_lake(self, spark_df, max_record_per_file="10000"):
"""
Append data into Delta lakes
:param spark_df: Pyspark Dataframe
:param max_record_per_file: str ie max_record_per_file= "10000"
:return: Bool
"""
spark_df.write.format("delta") \
.mode('append') \
.option("maxRecordsPerFile", max_record_per_file) \
.save(self.delta_lake_path)
return True
def update_records_delta_lake(self, condition="", value_to_set={}):
"""
Set the value on delta lake
:param condition : Str Example: condition="emp_id = '3'"
:param value_to_set: Dict IE value_to_set={"employee_name": "'THIS WAS UPDATE ON DELTA LAKE'"}
:return: Bool
"""
self.__generate_delta_df()
self.delta_df.update(condition, value_to_set)
return True
def upsert_records_delta_lake(self, old_data_key, new_data_key, new_spark_df):
"""
Find one and update into delta lake
If records is found it will update if not it will insert into delta lakes
See Examples on How to use this
:param old_data_key: Key is nothing but Column on which you want to merge or upsert data into delta lake
:param new_data_key: Key is nothing but Column on which you want to merge or upsert data into delta lake
:param new_spark_df: Spark DataFrame
:return: Bool
"""
self.__generate_delta_df()
dfUpdates = new_spark_df
self.delta_df.alias('oldData') \
.merge(dfUpdates.alias('newData'), f'oldData.{old_data_key} = newData.{new_data_key}') \
.whenMatchedUpdateAll() \
.whenNotMatchedInsertAll() \
.execute()
return True
def delete_records_delta_lake(self, condition=""):
"""
Set the value on delta lake
:param condition:Str IE condition="emp_id = '4'"
:return:Bool
"""
self.__generate_delta_df()
self.delta_df.delete(condition)
return True
def read_delta_lake(self):
"""
Reads from Delta lakes
:return: Spark DF
"""
df_read = self.spark.read.format("delta").load(self.delta_lake_path)
return df_read
def __create_spark_session(self):
self.spark = SparkSession \
.builder \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.databricks.delta.retentionDurationCheck.enabled", "false") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.config("spark.delta.logStore.s3.impl", "io.delta.storage.S3DynamoDBLogStore") \
.getOrCreate()
return self.spark
def main():
try:
from awsglue.job import Job
from awsglue.utils import getResolvedOptions
from awsglue.dynamicframe import DynamicFrame
from awsglue.context import GlueContext
except Exception as e:pass
helper = DeltaLakeHelper(delta_lake_path="s3a://glue-learn-begineers/deltalake/delta_table")
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
spark = helper.spark
sc = spark.sparkContext
glueContext = GlueContext(sc)
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# ====================================================
"""Create Spark Data Frame """
# ====================================================
data = impleDataUpd = [
(1, "this is insert 1 ", "Sales", "RJ", 81000, 30, 23000, 827307999),
(2, "this is insert 2", "Engineering", "RJ", 79000, 53, 15000, 1627694678),
(3, "this is insert 3", "Engineering", "RJ", 79000, 53, 15000, 1627694678),
(4, "this is insert 3", "Engineering", "RJ", 79000, 53, 15000, 1627694678),
]
columns = ["emp_id", "employee_name", "department", "state", "salary", "age", "bonus", "ts"]
df_write = spark.createDataFrame(data=data, schema=columns)
helper.insert_overwrite_records_delta_lake(spark_df=df_write)
# ====================================================
"""Appending """
# ====================================================
data = impleDataUpd = [
(5, "this is append", "Engineering", "RJ", 79000, 53, 15000, 1627694678),
]
columns = ["emp_id", "employee_name", "department", "state", "salary", "age", "bonus", "ts"]
df_append = spark.createDataFrame(data=data, schema=columns)
helper.append_records_delta_lake(spark_df=df_append)
# ====================================================
"""READ FROM DELTA LAKE """
# ====================================================
df_read = helper.read_delta_lake()
print("READ", df_read.show())
# ====================================================
"""UPDATE DELTA LAKE"""
# ====================================================
helper.update_records_delta_lake(condition="emp_id = '3'",
value_to_set={"employee_name": "'THIS WAS UPDATE ON DELTA LAKE'"})
# ====================================================
""" DELETE DELTA LAKE"""
# ====================================================
helper.delete_records_delta_lake(condition="emp_id = '4'")
# ====================================================
""" FIND ONE AND UPDATE OR UPSERT DELTA LAKE """
# ====================================================
new_data = [
(2, "this is update on delta lake ", "Sales", "RJ", 81000, 30, 23000, 827307999),
(11, "This should be append ", "Engineering", "RJ", 79000, 53, 15000, 1627694678),
]
columns = ["emp_id", "employee_name", "department", "state", "salary", "age", "bonus", "ts"]
usr_up_df = spark.createDataFrame(data=new_data, schema=columns)
helper.upsert_records_delta_lake(old_data_key='emp_id',
new_data_key='emp_id',
new_spark_df=usr_up_df)
# ====================================================
""" Compaction DELTA Prune Older Version and Create larger Files """
# ====================================================
helper.compact_table(num_of_files=2)
helper.delete_older_files_versions()
# ====================================================
""" Create Manifest File for Athena """
# ====================================================
helper.generate_manifest_files()
job.commit()
main()
Please advice