I have a strange problem with some AVX / AVX2 codes that I am working on. I have set up a test application console developed in cpp (Visual Studio 2017 on Windows 7) with the aim of comparing the routines written in Cpp with the equivalent routine written with the set-instruction AVX / AVX2; each routine is timed. A first problem: the timed time of the single routine changes according to the position of the call of the same;
void TraditionalAVG_UncharToDouble(const unsigned char *vec1, const unsigned char *vec2, double* doubleArray, const unsigned int length) {
int sumTot = 0;
double* ptrDouble = doubleArray;
for (unsigned int packIdx = 0; packIdx < length; ++packIdx) {
*ptrDouble = ((double)(*(vec1 + packIdx) + *(vec2 + packIdx)))/ ((double)2);
ptrDouble++;
}
}
void AVG_uncharToDoubleArray(const unsigned char *vec1, const unsigned char *vec2, double* doubleArray, const unsigned int length) {
//constexpr unsigned int memoryAlignmentBytes = 32;
constexpr unsigned int bytesPerPack = 256 / 16;
unsigned int packCount = length / bytesPerPack;
double* ptrDouble = doubleArray;
__m128d divider=_mm_set1_pd(2);
for (unsigned int packIdx = 0; packIdx < packCount; ++packIdx)
{
auto x1 = _mm_loadu_si128((const __m128i*)vec1);
auto x2 = _mm_loadu_si128((const __m128i*)vec2);
unsigned char index = 0;
while(index < 8) {
index++;
auto x1lo = _mm_cvtepu8_epi64(x1);
auto x2lo = _mm_cvtepu8_epi64(x2);
__m128d x1_pd = int64_to_double_full(x1lo);
__m128d x2_pd = int64_to_double_full(x2lo);
_mm_store_pd(ptrDouble, _mm_div_pd(_mm_add_pd(x1_pd, x2_pd), divider));
ptrDouble = ptrDouble + 2;
x1 = _mm_srli_si128(x1, 2);
x2 = _mm_srli_si128(x2, 2);
}
vec1 += bytesPerPack;
vec2 += bytesPerPack;
}
for (unsigned int ii = 0 ; ii < length % packCount; ++ii)
{
*(ptrDouble + ii) = (double)(*(vec1 + ii) + *(vec2 + ii))/ (double)2;
}
}
... on main ...
timeAvg02 = 0;
Start_TimerMS();
AVG_uncharToDoubleArray(unCharArray, unCharArrayBis, doubleArray, N);
End_TimerMS(&timeAvg02);
std::cout << "AVX2_AVG UncharTodoubleArray:: " << timeAvg02 << " ms" << std::endl;
//printerDouble("AvxDouble", doubleArray, N);
std::cout << std::endl;
timeAvg01 = 0;
Start_TimerMS3();
TraditionalAVG_UncharToDouble(unCharArray, unCharArrayBis, doubleArray, N);
End_TimerMS3(&timeAvg01);
std::cout << "Traditional_AVG UncharTodoubleArray: " << timeAvg01 << " ms" << std::endl;
//printerDouble("TraditionalAvgDouble", doubleArray, N);
std::cout << std::endl;
the second problem is that routines written in AVX2 are slower than routines written in cpp. The images represent the results of the two tests
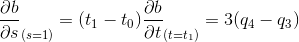
How can I overcome this strange behavior? What is the reason behind it?