Edit 1:
With your updated example data you have (at least) two options: you can separate each column, or you can pivot_longer() the data and group the "scores" together. E.g.
library(tidyr)
df <- data.frame(subjects = 1:12,
Why_are_you_not_happy =
c(1,2,"1,2,5",5,1,2,"3,4",3,2,"1,5",3,4),
why_are_you_sad =
c("1,2,3",1,2,3,"4,5,3",2,1,4,3,1,1,1))
df
#> subjects Why_are_you_not_happy why_are_you_sad
#> 1 1 1 1,2,3
#> 2 2 2 1
#> 3 3 1,2,5 2
#> 4 4 5 3
#> 5 5 1 4,5,3
#> 6 6 2 2
#> 7 7 3,4 1
#> 8 8 3 4
#> 9 9 2 3
#> 10 10 1,5 1
#> 11 11 3 1
#> 12 12 4 1
df1 <- df %>%
separate(Why_are_you_not_happy,
sep = ",", into = c("Why_are_you_not_happy_1",
"Why_are_you_not_happy_2",
"Why_are_you_not_happy_3")) %>%
separate(why_are_you_sad,
sep = ",", into = c("why_are_you_sad_1",
"why_are_you_sad_2",
"why_are_you_sad_3"))
#> Warning: Expected 3 pieces. Missing pieces filled with `NA` in 11 rows [1, 2, 4,
#> 5, 6, 7, 8, 9, 10, 11, 12].
#> Warning: Expected 3 pieces. Missing pieces filled with `NA` in 10 rows [2, 3, 4,
#> 6, 7, 8, 9, 10, 11, 12].
df1
#> subjects Why_are_you_not_happy_1 Why_are_you_not_happy_2
#> 1 1 1 <NA>
#> 2 2 2 <NA>
#> 3 3 1 2
#> 4 4 5 <NA>
#> 5 5 1 <NA>
#> 6 6 2 <NA>
#> 7 7 3 4
#> 8 8 3 <NA>
#> 9 9 2 <NA>
#> 10 10 1 5
#> 11 11 3 <NA>
#> 12 12 4 <NA>
#> Why_are_you_not_happy_3 why_are_you_sad_1 why_are_you_sad_2
#> 1 <NA> 1 2
#> 2 <NA> 1 <NA>
#> 3 5 2 <NA>
#> 4 <NA> 3 <NA>
#> 5 <NA> 4 5
#> 6 <NA> 2 <NA>
#> 7 <NA> 1 <NA>
#> 8 <NA> 4 <NA>
#> 9 <NA> 3 <NA>
#> 10 <NA> 1 <NA>
#> 11 <NA> 1 <NA>
#> 12 <NA> 1 <NA>
#> why_are_you_sad_3
#> 1 3
#> 2 <NA>
#> 3 <NA>
#> 4 <NA>
#> 5 3
#> 6 <NA>
#> 7 <NA>
#> 8 <NA>
#> 9 <NA>
#> 10 <NA>
#> 11 <NA>
#> 12 <NA>
This is what I think you should use for MCA, e.g.
library(FactoMineR)
library(factoextra)
#> Loading required package: ggplot2
results <- MCA(df1[,2:7])

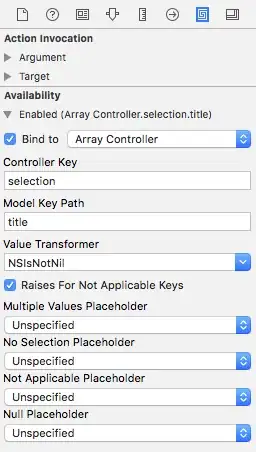
# Check eigenvalues to see %var for each dimension
fviz_eig(results)
Second approach for handling the data that 'works better' for plotting with e.g. ggplot:
df2 <- df %>%
pivot_longer(-subjects,
names_to = "Category",
values_to = "Score") %>%
separate(Score, sep = ",",
into = c("Score_1", "Score_2", "Score_3"))
#> Warning: Expected 3 pieces. Missing pieces filled with `NA` in 21 rows [1, 3, 4,
#> 6, 7, 8, 9, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, ...].
df2
#> # A tibble: 24 × 5
#> subjects Category Score_1 Score_2 Score_3
#> <int> <chr> <chr> <chr> <chr>
#> 1 1 Why_are_you_not_happy 1 <NA> <NA>
#> 2 1 why_are_you_sad 1 2 3
#> 3 2 Why_are_you_not_happy 2 <NA> <NA>
#> 4 2 why_are_you_sad 1 <NA> <NA>
#> 5 3 Why_are_you_not_happy 1 2 5
#> 6 3 why_are_you_sad 2 <NA> <NA>
#> 7 4 Why_are_you_not_happy 5 <NA> <NA>
#> 8 4 why_are_you_sad 3 <NA> <NA>
#> 9 5 Why_are_you_not_happy 1 <NA> <NA>
#> 10 5 why_are_you_sad 4 5 3
#> # … with 14 more rows
library(ggplot2)
# convert subjects from an integer to a factor
df2$subjects <- factor(df2$subjects)
group_labels <- c("Why_are_you_not_happy" = "Why are you not happy?",
"why_are_you_sad" = "Why are you sad?")
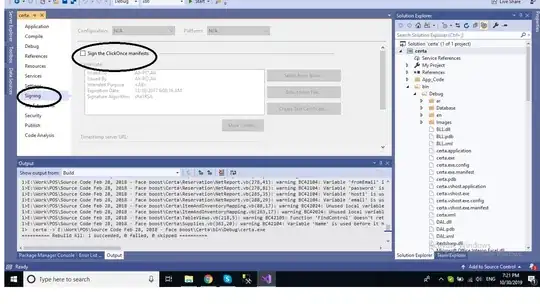
df2 %>%
pivot_longer(-c(subjects, Category),
names_to = "Score_number",
values_to = "Answer") %>%
na.omit() %>%
ggplot(aes(x = subjects, y = Answer,
fill = Category)) +
geom_tile(color = "white") +
geom_vline(xintercept = seq(0.5, 11.5, 1),
color = "black") +
geom_hline(yintercept = seq(0.5, 4.5, 1),
color = "black") +
scale_fill_discrete(labels = group_labels,
name = "") +
theme_bw(base_size = 16) +
theme(legend.position = "none",
panel.grid = element_blank()) +
coord_cartesian(expand = 0) +
facet_wrap(~Category, nrow = 2,
labeller = labeller(Category = group_labels))
Created on 2022-10-06 by the reprex package (v2.0.1)
Original answer:
It sounds like you want the separate() function from the tidyr package, e.g.
library(tidyr)
df <- data.frame(subjects = 1:12,
Why_are_you_not_happy = c(1,2,"1,2,5",5,1,2,"3,4",3,2,"1,5",3,4))
df
#> subjects Why_are_you_not_happy
#> 1 1 1
#> 2 2 2
#> 3 3 1,2,5
#> 4 4 5
#> 5 5 1
#> 6 6 2
#> 7 7 3,4
#> 8 8 3
#> 9 9 2
#> 10 10 1,5
#> 11 11 3
#> 12 12 4
df %>%
separate(Why_are_you_not_happy,
sep = ",", into = c("Answer_1",
"Answer_2",
"Answer_3"))
#> Warning: Expected 3 pieces. Missing pieces filled with `NA` in 11 rows [1, 2, 4,
#> 5, 6, 7, 8, 9, 10, 11, 12].
#> subjects Answer_1 Answer_2 Answer_3
#> 1 1 1 <NA> <NA>
#> 2 2 2 <NA> <NA>
#> 3 3 1 2 5
#> 4 4 5 <NA> <NA>
#> 5 5 1 <NA> <NA>
#> 6 6 2 <NA> <NA>
#> 7 7 3 4 <NA>
#> 8 8 3 <NA> <NA>
#> 9 9 2 <NA> <NA>
#> 10 10 1 5 <NA>
#> 11 11 3 <NA> <NA>
#> 12 12 4 <NA> <NA>
Or, perhaps in long format? E.g.
df %>%
separate(Why_are_you_not_happy,
sep = ",", into = c("Answer_1",
"Answer_2",
"Answer_3")) %>%
pivot_longer(-subjects) %>%
na.omit()
#> Warning: Expected 3 pieces. Missing pieces filled with `NA` in 11 rows [1, 2, 4,
#> 5, 6, 7, 8, 9, 10, 11, 12].
#> # A tibble: 16 × 3
#> subjects name value
#> <int> <chr> <chr>
#> 1 1 Answer_1 1
#> 2 2 Answer_1 2
#> 3 3 Answer_1 1
#> 4 3 Answer_2 2
#> 5 3 Answer_3 5
#> 6 4 Answer_1 5
#> 7 5 Answer_1 1
#> 8 6 Answer_1 2
#> 9 7 Answer_1 3
#> 10 7 Answer_2 4
#> 11 8 Answer_1 3
#> 12 9 Answer_1 2
#> 13 10 Answer_1 1
#> 14 10 Answer_2 5
#> 15 11 Answer_1 3
#> 16 12 Answer_1 4
Created on 2022-10-05 by the reprex package (v2.0.1)