I tried to reproduce the above and I got the same error.
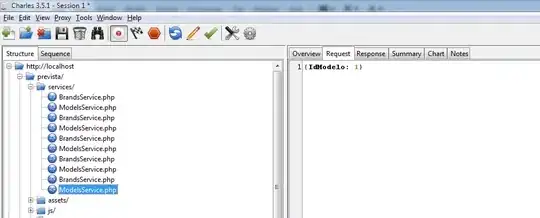
when I expand the error, it is showing the table as parquet. I tried to convert it to delta table but got the same error even after that.
If you are not able to resolve the above error, you can try this workaround with the help of Pyspark dataframe.
This is my sample delta table with some duplicate values.
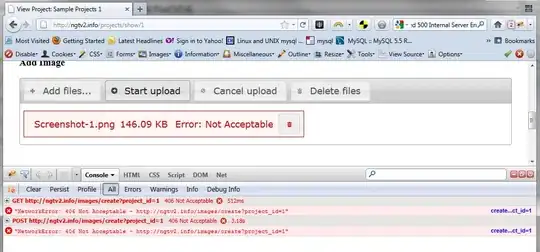
First select the rows which has rownum as 1 from CTE. Then overwrite these values with your delta table.
Selecting required rows:
Code:
%sql
with cte as
(
select *,row_number() over(Partition by ID order by Name) as row_num from mytable
) select Id,Name,Age from cte where row_num=1

_sqldf is a pyspark dataframe which has latest SQL cell result.
Use this dataframe and overwrite to your delta table.
%python
_sqldf.write.mode("overwrite").format("delta").save("delta table path")