Although this is a really old question with many answers, but you can do it without the use of external tools like sed or awk (hence platform-independent). You can "simply" do it with gnuplot (even with the version at that time of OP's question: gnuplot 4.4.0, March 2010).
However, from your example data and description it is not clear whether the value of interest
- is strictly in the 12th column or
- is always in the last column or
- could be in any column but always trailed with
pts
For all 3 cases there are gnuplot-only (hence platform-independent) solutions.
Assumption is that column separator is space.
ad 1. The simplest solution: with u 1:12, gnuplot will simply ignore non-numerical and column values, e.g. like 45pts will be interpreted as 45.
ad 2. and 3. If you extract the last column as string, gnuplot will fail and stop if you want to convert a non-numerical value via real() into a floating point number. Hence, you have to test yourself via your own function isNumber() if the column value at least starts with a number and hence can be converted by real(). In case the string is not a number you could set the value to 1/0 or NaN. However, in earlier gnuplot versions the line of a lines(points) plot will be interrupted.
Whereas in newer gnuplot versions (>=4.6.0) you could set the value to NaN and avoid interruptions via set datafile missing NaN which, however, is not available in gnuplot 4.4.
Furthermore, in gnuplot 4.4 NaN is simply set to 0.0 (GPVAL_NAN = 0.0).
You can workaround this with this "trick" which is also used below.
Data: SO7353702.dat
2010/01/12/ 12:00 some un related alapha 129495 and the interesting value 45pts
2010/01/12/ 15:00 some un related alapha 129495 and no interesting value
2010/01/13/ 09:00 some un related alapha 345678 and the interesting value 60pts
2010/01/15/ 09:00 some un related alapha 345678 62pts and nothing
2010/01/17/ 09:00 some un related alapha 345678 and nothing
2010/01/18/ 09:00 some un related alapha 345678 and the interesting value 70.5pts
2010/01/19/ 09:00 some un related alapha 345678 and the interesting value extra extra 64pts
2010/01/20/ 09:00 some un related alapha 345678 and the interesting value 0.66e2pts
Script: (works for gnuplot>=4.4.0, March 2010)
### extract numbers without external tools
reset
FILE = "SO7353702.dat"
set xdata time
set timefmt "%Y/%m/%d/ %H:%M"
set format x "%b %d"
isNumber(s) = strstrt('+-.',s[1:1])>0 && strstrt('0123456789',s[2:2])>0 \
|| strstrt('0123456789',s[1:1])>0
# Version 1:
plot FILE u 1:12 w lp pt 7 ti "value in the 12th column"
pause -1
# Version 2:
set datafile separator "\t"
getLastValue(col) = (s=word(strcol(col),words(strcol(col))), \
isNumber(s) ? (t0=t1, real(s)) : (y0))
plot t0=NaN FILE u (t1=timecolumn(1), y0=getLastValue(1), t0) : (y0) w lp pt 7 \
ti "value in the last column"
pause -1
# Version 3:
getPts(s) = (c=strstrt(s,"pts"), c>0 ? (r=s[1:c-1], p=word(r,words(r)), isNumber(p) ? \
(t0=t1, real(p)) : y0) : y0)
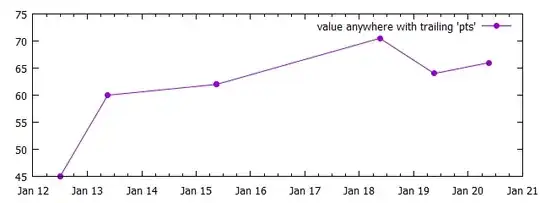
plot t0=NaN FILE u (t1=timecolumn(1),y0=getPts(strcol(1)),t0):(y0) w lp pt 7 \
ti "value anywhere with trailing 'pts'"
### end of script
Result:
Version 1:

Version 2:

Version 3: