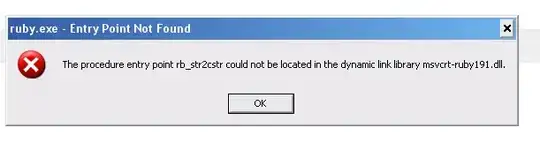
I am able to use the transformer SpeechToTextSDK of SynapseML to convert wav files to text in Databricks. However, with mp3, I have the error : 0x27 (SPXERR_GSTREAMER_INTERNAL_ERROR).
In their documentation (https://mmlspark.blob.core.windows.net/docs/0.10.0/pyspark/synapse.ml.cognitive.html#module-synapse.ml.cognitive.SpeechToTextSDK), it is clearly said that supports mp3 also :
I have a list of audio files with different format :
wasbs://test@blobstorage.blob.core.windows.net/file1.mp3 wasbs://test@blobstorage.blob.core.windows.net/file2.wav
I used the following transformer in SpeechToTextSDK with the code below :
import synapse.ml
from synapse.ml.cognitive import *
stt = (SpeechToTextSDK()
.setSubscriptionKey(YOUR_API_KEY)
.setLocation(REGION)
.setOutputCol("text")
.setAudioDataCol("wavbytes")
.setFormatCol("format")
.setLanguageCol("lang")
.setStreamIntermediateResults(False)
)
results = stt.transform(wav_audio_list)
Any one has an idea?
many thanks in advance,