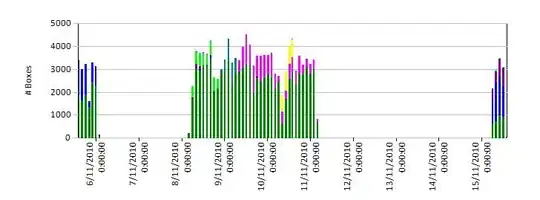
This is the Example of the pdf from which i want to extraxct data.
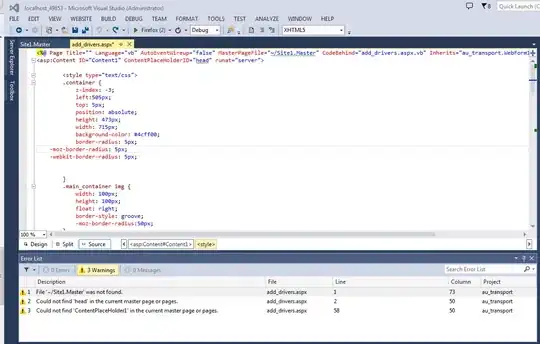
This is what i have tried
import PyPDF2 as pypdf
pdfobject=open('w10.pdf','rb')
for i in range(1,pdf.getNumPages()-1):
print(pdf.getPage(i).extractText())
My Result city:Mohali
population 2022
st:456
ID No. 8511
H Code IPRTAHNRE
I Code #5477/7985
Name Sanjeev
Father's Name Ashwani
House No. 121
Age 22
Sex Male
ID No. 2500
H Code IPWERNER
I Code *2/5464
Name Asdff
Father's Name sgdgd
House No. 154
Age 23
Sex Male
ID No. 4564
H Code IPRAFHNR
I Code #4577/789
Name Avadhesh
Father's Name Ajor NAth
House No. 12
Age 24
Sex Male
Expected Result