original image
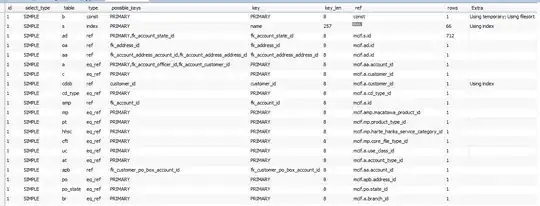
img = cv2.imread('eng2.png')
d = pytesseract.image_to_data(img, output_type=Output.DICT)
n_boxes = len(d['level'])
for i in range(n_boxes):
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
plt.figure(figsize=(10,10))
plt.imshow(img)
The above code produces this image. Now in the image there are two coordinates one for each word and other for the whole text. I would like to get the coordinates for the whole text (sentences in each line or the whole paragraph

This is what I have tried
box = pd.DataFrame(d) #dict to dataframe
box['text'].replace('', np.nan, inplace=True) #replace empty values by NaN
box= box.dropna(subset = ['text']) #delete rows with NaN
print(box)
def lineup(boxes):
linebox = None
for _, box in boxes.iterrows():
if linebox is None: linebox = box # first line begins
elif box.top <= linebox.top+linebox.height: # box in same line
linebox.top = min(linebox.top, box.top)
linebox.width = box.left+box.width-linebox.left
linebox.heigth = max(linebox.top+linebox.height, box.top+box.height)-linebox.top
linebox.text += ' '+box.text
else: # box in new line
yield linebox
linebox = box # new line begins
yield linebox # return last line
lineboxes = pd.DataFrame.from_records(lineup(box))
Output dataframe
n_boxes = len(lineboxes['level'])
for i in range(n_boxes):
(x, y, w, h) = (lineboxes['left'][i], lineboxes['top'][i], lineboxes['width'][i], lineboxes['height'][i])
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
plt.figure(figsize=(10,10))
plt.imshow(img)
There seems to be no difference between the original coordinates and after joining all the coordinates

How can i get the coordinates of the whole text (sentences in each line or the whole paragraph) using pytesseract library?



