How does this architecture handle a large backlog of pdfs to be processed by AWS Textract? If there's a large backlog of messages in the first queue, the first lambda (scheduled to run every x minutes) would start picking up messages to call and execute asynchronous StartDocumentAnalysis.
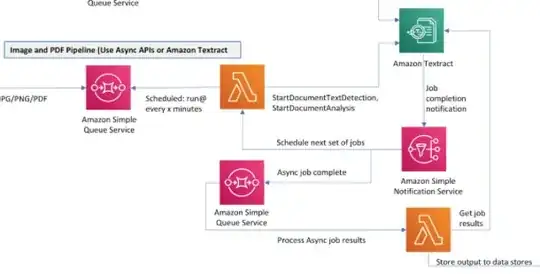
The shortcoming of having the lambda with a schedule is that what happens if the pdf document is large and Textract takes longer than x minutes for it to process the document? In this scenario the lambda would consume the next message in the queue, start another async StartDocumentAnalysis call. There's the potential of hitting the Textract default concurrency limit of 2 StartDocumentAnalysis at a time.
I can make x minutes longer but is there a way to make this pipeline smarter? As in logic within the lambda to check the current number of concurrent Textract process running, then if there's enough concurrency, have the lambda consume the next message in the queue?
My solution ideally would need to account for 1000s of PDF documents uploaded to the source bucket, which would exceed the max region capacity of 600.