I am trying to create a retention table like the following using SQL in Big Query but with MONTHLY cohorts;
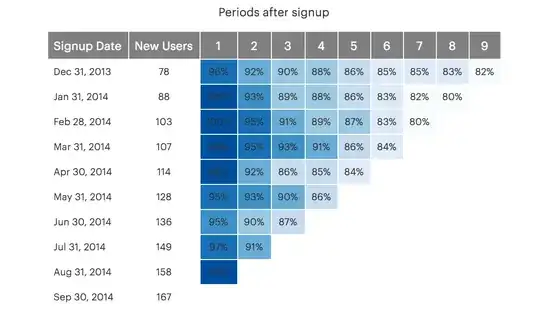
I have the following columns to use in my dataset, I am only using one table and it's name is 'curious-furnace-341507.TEST.Test_Dataset_-_Orders'
| order_date | order_id | customer_id |
|---|---|---|
| 2020-01-02 | 12345 | 6789 |
I do not need the new user column and the data goes through June 2020 I think ideally a cohort month column that lists January-June cohorts and then 5 periods across.
I have tried so many different things and keep getting errors in BigQuery I think I am approaching it all wrong. The online queries I am trying to pull from seem to use dates rather than months which is also causing some confusion as I think I need to truncate my date column to months only in the query?
Does anyone have a go-to query that will work in BigQuery for a retention table or can help me approach this? Thanks!