I use Tesseract5 and pytesseract
My picture is:
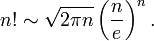
I tried different methods for pre-processing: scale, resize, binarization, blur, dilate and etc
In the same time it works fine for "!?#@abc!!"
Will be glad of any advice
I use Tesseract5 and pytesseract
My picture is:
I tried different methods for pre-processing: scale, resize, binarization, blur, dilate and etc
In the same time it works fine for "!?#@abc!!"
Will be glad of any advice
Wow, that's a lot of punctuation!
Models of English language text will predict that "bang bang bang bang, followed by bang" occurs with very low probability. This impacts recognition accuracy.
For such specialized inputs, you will want to train a new language model: https://stackoverflow.com/a/13556952/8431111