Note: I may have chosen the wrong word in the title; perhaps I'm really talking about polynomial growth here. See the benchmark result at the end of this question.
Let's start with these three recursive generic interfaces† that represent immutable stacks:
interface IStack<T>
{
INonEmptyStack<T, IStack<T>> Push(T x);
}
interface IEmptyStack<T> : IStack<T>
{
new INonEmptyStack<T, IEmptyStack<T>> Push(T x);
}
interface INonEmptyStack<T, out TStackBeneath> : IStack<T>
where TStackBeneath : IStack<T>
{
T Top { get; }
TStackBeneath Pop();
new INonEmptyStack<T, INonEmptyStack<T, TStackBeneath>> Push(T x);
}
I've created straightforward implementations EmptyStack<T>, NonEmptyStack<T,TStackBeneath>.
Update #1: See the code below.
I've noticed the following things about their runtime performance:
- Pushing 1,000 items onto an
EmptyStack<int>for the first time takes more than 7 seconds. - Pushing 1,000 items onto an
EmptyStack<int>takes virtually no time at all afterwards. - Performance gets exponentially worse the more items I push onto the stack.
Update #2:
I've finally performed a more precise measurement. See the benchmark code and results below.
I've only discovered during these tests that .NET 3.5 doesn't seem to allow generic types with a recursion depth ≥ 100. .NET 4 doesn't seem to have this restriction.
The first two facts make me suspect that the slow performance is not due to my implementation, but rather to the type system: .NET has to instantiate 1,000 distinct closed generic types, ie.:
EmptyStack<int>NonEmptyStack<int, EmptyStack<int>>NonEmptyStack<int, NonEmptyStack<int, EmptyStack<int>>>NonEmptyStack<int, NonEmptyStack<int, NonEmptyStack<int, EmptyStack<int>>>>- etc.
Questions:
- Is my above assessment correct?
- If so, why does instantiation of generic types such as
T<U>,T<T<U>>,T<T<T<U>>>, and so on get exponentially slower the deeper they are nested? - Are CLR implementations other than .NET (Mono, Silverlight, .NET Compact etc.) known to exhibit the same characteristics?
†) Off-topic footnote: These types are quite interesting btw. because they allow the compiler to catch certain errors such as:
stack.Push(item).Pop().Pop(); // ^^^^^^ // causes compile-time error if 'stack' is not known to be non-empty.Or you can express requirements for certain stack operations:
TStackBeneath PopTwoItems<T, TStackBeneath> (INonEmptyStack<T, INonEmptyStack<T, TStackBeneath> stack)
Update #1: Implementation of the above interfaces
internal class EmptyStack<T> : IEmptyStack<T>
{
public INonEmptyStack<T, IEmptyStack<T>> Push(T x)
{
return new NonEmptyStack<T, IEmptyStack<T>>(x, this);
}
INonEmptyStack<T, IStack<T>> IStack<T>.Push(T x)
{
return Push(x);
}
}
// ^ this could be made into a singleton per type T
internal class NonEmptyStack<T, TStackBeneath> : INonEmptyStack<T, TStackBeneath>
where TStackBeneath : IStack<T>
{
private readonly T top;
private readonly TStackBeneath stackBeneathTop;
public NonEmptyStack(T top, TStackBeneath stackBeneathTop)
{
this.top = top;
this.stackBeneathTop = stackBeneathTop;
}
public T Top { get { return top; } }
public TStackBeneath Pop()
{
return stackBeneathTop;
}
public INonEmptyStack<T, INonEmptyStack<T, TStackBeneath>> Push(T x)
{
return new NonEmptyStack<T, INonEmptyStack<T, TStackBeneath>>(x, this);
}
INonEmptyStack<T, IStack<T>> IStack<T>.Push(T x)
{
return Push(x);
}
}
Update #2: Benchmark code and results
I used the following code to measure recursive generic type instantiation times for .NET 4 on a Windows 7 SP 1 x64 (Intel U4100 @ 1.3 GHz, 4 GB RAM) notebook. This is a different, faster machine than the one I originally used, so the results do not match with the statements above.
Console.WriteLine("N, t [ms]");
int outerN = 0;
while (true)
{
outerN++;
var appDomain = AppDomain.CreateDomain(outerN.ToString());
appDomain.SetData("n", outerN);
appDomain.DoCallBack(delegate {
int n = (int)AppDomain.CurrentDomain.GetData("n");
var stopwatch = new Stopwatch();
stopwatch.Start();
IStack<int> s = new EmptyStack<int>();
for (int i = 0; i < n; ++i)
{
s = s.Push(i); // <-- this "creates" a new type
}
stopwatch.Stop();
long ms = stopwatch.ElapsedMilliseconds;
Console.WriteLine("{0}, {1}", n, ms);
});
AppDomain.Unload(appDomain);
}
(Each measurement is taken in a separate app domain because this ensures that all runtime types will have to be re-created in each loop iteration.)
Here's a X-Y plot of the output:
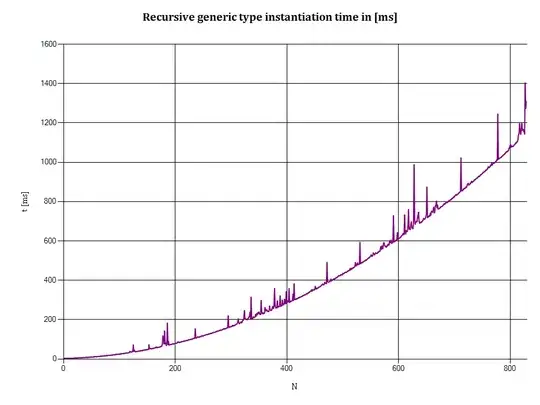
Horizontal axis: N denotes the depth of type recursion, i.e.:
- N = 1 indicates a
NonEmptyStack<EmptyStack<T>> - N = 2 indicates a
NonEmptyStack<NonEmptyStack<EmptyStack<T>>> - etc.
- N = 1 indicates a
Vertical axis: t is the time (in milliseconds) required to push N integers onto a stack. (The time needed to create runtime types, if that actually happens, is included in this measurement.)