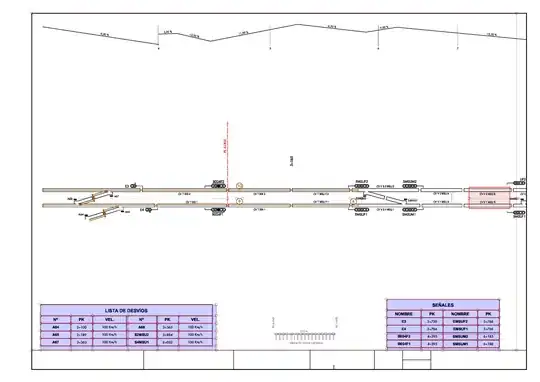
I am new to pdfplumber, and I have fallen amazed under how it extracts text from tables.
Its easy to work for all-page tables, but in my case, I am using some topological schematics with somes tables inside.
It fails to extract the first column and the last row of every table in document. I have tried to tweak several configuration parameters in table_settings variable, unluckily I haven't been able to achieve any better result (in my case, the rest of texts in the schematic is considered as a table in case I use "text" instead of "lines").
Any help with this? I am using Python 3.9.8 and the pdf for testing can be found in: schematic.pdf
The source code is next:
import pdfplumber
pdf_file = "Schematic.pdf"
tables=[]
with pdfplumber.open(pdf_file) as pdf:
pages = pdf.pages
tbl = pages[0].extract_tables()
print(f'{tbl}')