You can create a mask for a specific column first (I edited your 2nd line a bit), then create a new 'Match' column with all values initialized to 'No Match', and finally, change the values to your desired format ("Column||Value") for rows that are returned after applying the mask. I implemented this in the following sample code:
def match_column(df, column_name):
column_mask = df.astype(str).applymap(lambda x: any(y in x for y in ['Chann','Midm']))[column_name]
df['Match'] = 'No Match'
df.loc[column_mask, 'Match'] = column_name + ' || ' + df[column_name]
return df
df = {
'Segment': ['Government', 'Government', 'Midmarket', 'Midmarket', 'Government', 'Channel Partners'],
'Country': ['Canada', 'Germany', 'France', 'Canada', 'France', 'France']
}
df = pd.DataFrame(df)
display(df)
df = match_column(df, 'Segment')
display(df)
Output:
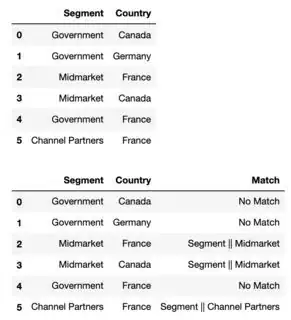
However, this only works for a single column. I don't know what output you want for cases when there are matches in multiple columns (if you can, please specify).
UPDATE:
If you want to use a list of columns as input and match with the first instance, you can use this instead:
def match_first_column(df, column_list):
df['Match'] = 'No Match'
# iterate over rows
for index, row in df.iterrows():
# iterate over column names
for column_name in column_list:
column_value = row[column_name]
substrings = ['Chann', 'Midm', 'Fran']
# if a match is found
if any(x in column_value for x in substrings):
# add match string
df.loc[index, 'Match'] = column_name + ' || ' + column_value
# stop iterating and move to next row
break
return df
df = {
'Segment': ['Government', 'Government', 'Midmarket', 'Midmarket', 'Government', 'Channel Partners'],
'Country': ['Canada', 'Germany', 'France', 'Canada', 'France', 'France']
}
df = pd.DataFrame(df)
display(df)
column_list= df.columns.tolist()
match_first_column(df, column_list)
Output:



{kind=link}