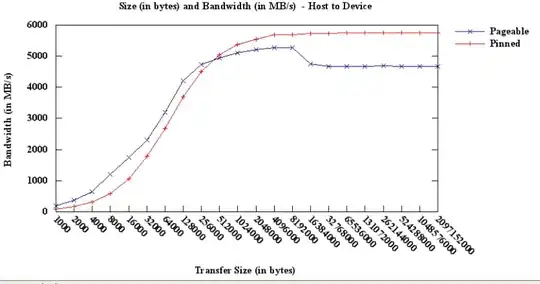
I am running host to device bandwidthtests for different sizes of data, and have noticed an increased bandwidth when the host memory is pinned against pageable. Following is my plot of bandwidth in MB/s vs data transfer size in bytes. One could notice that for small amount of data (<300K) pageable fares better than pinned...is it related to memory allocation by the O/S? This bandwidthtest program is from NVidia's code sample sdk (with slight modifications from my side), and I am testing against Tesla C2050 using CUDA 4.0. The O/S is 64-bit Linux.