I am implementing a bidirectional Dijkstra's algorithm and having issues understanding how the various implementations of the stopping condition work out.
Take this graph for example, where we're starting from node A, targetting node J. Below the graph I have listed the cluster (processed) and relaxed (fringes) nodes at the time the algorithm stops:
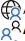
The accepted answer to “Bidirectional Dijkstra” by NetworkX explains that the algorithm stops when the same node has been processed in both directions. In my graph that will be Node F. If that were the case, the algorithm stops after finding the shortest path of length 9 going from A-B-C...H-I-J. But this wouldn't be the shortest path because A-J have a direct edge of length 8 which is never taken because the weight 8 is never popped from the priority queue.
Even in this Java implementation on github of Dijksta's bi-directional algorithm, the stopping condition is:
double mtmp = DISTANCEA.get(OPENA.min()) +
DISTANCEB.get(OPENB.min());
if (mtmp >= bestPathLength) return PATH;
This algorithm stops when the top node weights -- from each front and backward queue -- add up to at least the best path length so far. But this wouldn't return the correct shortest path either. Because in that case it will be node G(6) and E(5) totalling to 11, which is greater than the best path so far of length 9.
I don't understand that seemingly both of these stopping conditions yield an incorrect shortest path. I am not sure what I am misunderstanding.
What is a good stopping condition for Dijkstra's bidirectional algorithm? Also, what would be a stopping condition for bidirectional A*?