I have the following (sample) dataset:
df <- data.table(
firm = rep(c("A","B"),each=20),
year = c(1994,1994,1994,1994,1994,1994,1994,1994,1994,1994,2000,2000,2000,2002,2002,2002,2003,2003,2003,2003,1975,1975,1975,1975,1975,1975,1976,1976,1977,1977,1977,1977,1977,1977,1977,1977,1977,1978,1978,1978),
patent_number=c(5505081,5505081,5606110,5606110,5837890,5837890,5837890,5837890,5837890,5837890,6725912,6725912,6725912,6748800,6748800,6748800,7153136,6997049,6997049,6997049,4026555,4026555,4026555,4026555,4026555,4026555,4155095,4155095,4137556,4137556,4137556,4137556,4137556,4137556,4137556,4137556,4137556,4253157,4253157,4253157),
class=c("73","73","73","73","73","73","73","73","73","73","165","165","165","73","73","73","434","73","73","73","463","463","463","463","463","463","348","348","361","361","361","361","361","361","361","361","361","707","707","707"),
sub_class=c("147","12.07","12.08","147","116.03","184","185","186","198","210","144",
"147","140","147","E29.272","E29.309","59","147","E29.272","E29.309","3","168",
"473","960","552","31","701","593","91.2","72","58","59","111",
"222","93.05","117","709","104.1","93.25","552"),
sub_new_I = c(0,0,0,0,0,0,0,0,0,0,0,1,0,1,0,0,0,1,1,1,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,1)
)
> df
firm year patent_number class sub_class sub_new_I
1: A 1994 5505081 73 147 0
2: A 1994 5505081 73 12.07 0
3: A 1994 5606110 73 12.08 0
4: A 1994 5606110 73 147 0
5: A 1994 5837890 73 116.03 0
6: A 1994 5837890 73 184 0
7: A 1994 5837890 73 185 0
8: A 1994 5837890 73 186 0
9: A 1994 5837890 73 198 0
10: A 1994 5837890 73 210 0
11: A 2000 6725912 165 144 0
12: A 2000 6725912 165 147 1
13: A 2000 6725912 165 140 0
14: A 2002 6748800 73 147 1
15: A 2002 6748800 73 E29.272 0
16: A 2002 6748800 73 E29.309 0
17: A 2003 7153136 434 59 0
18: A 2003 6997049 73 147 1
19: A 2003 6997049 73 E29.272 1
20: A 2003 6997049 73 E29.309 1
21: B 1975 4026555 463 3 0
22: B 1975 4026555 463 168 0
23: B 1975 4026555 463 473 0
24: B 1975 4026555 463 960 0
25: B 1975 4026555 463 552 0
26: B 1975 4026555 463 31 0
27: B 1976 4155095 348 701 0
28: B 1976 4155095 348 593 0
29: B 1977 4137556 361 91.2 0
30: B 1977 4137556 361 72 0
31: B 1977 4137556 361 58 0
32: B 1977 4137556 361 59 0
33: B 1977 4137556 361 111 0
34: B 1977 4137556 361 222 0
35: B 1977 4137556 361 93.05 0
36: B 1977 4137556 361 117 0
37: B 1977 4137556 361 709 0
38: B 1978 4253157 707 104.1 0
39: B 1978 4253157 707 93.25 0
40: B 1978 4253157 707 552 1
The column sub_new_I indicates whether a firm has previously filed a patent in that specific subclass (by a binary indicator).
My goal is to apply a time discount to decrease the value of more distant history. The logic is that a subclass that appears 10 years ago is different from the one that was filed 2 years ago. To do this, I want to rely on an exponential discount with a power less than 1, explained as follows:
For example, Firm A has filed a patent (with patent_number = 6725912) in 2000 which includes subclass 147. The same subclass appears in year 1994 as well (patent_number=5606110). The indicator (sub_class_I) is therefore equal to 1 in year 2000. But applying the time discount, I want the indicator to be exp(-( (2000-1994)/5 ) )=0.301.
Essentially, the discount factor is given by this formula:
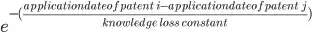
Here, the constant for knowledge loss is equal to 5. (This means that the denominator is equal to 5 in all calculations).
The desired output is, therefore:
> df
firm year patent_number class sub_class sub_new_I discounted_I
1: A 1994 5505081 73 147 0 0.0000
2: A 1994 5505081 73 12.07 0 0.0000
3: A 1994 5606110 73 12.08 0 0.0000
4: A 1994 5606110 73 147 0 0.0000
5: A 1994 5837890 73 116.03 0 0.0000
6: A 1994 5837890 73 184 0 0.0000
7: A 1994 5837890 73 185 0 0.0000
8: A 1994 5837890 73 186 0 0.0000
9: A 1994 5837890 73 198 0 0.0000
10: A 1994 5837890 73 210 0 0.0000
11: A 2000 6725912 165 144 0 0.0000
12: A 2000 6725912 165 147 1 0.3012
13: A 2000 6725912 165 140 0 0.0000
14: A 2002 6748800 73 147 1 0.6703
15: A 2002 6748800 73 E29.272 0 0.0000
16: A 2002 6748800 73 E29.309 0 0.0000
17: A 2003 7153136 434 59 0 0.0000
18: A 2003 6997049 73 147 1 0.8187
19: A 2003 6997049 73 E29.272 1 0.8187
20: A 2003 6997049 73 E29.309 1 0.8187
21: B 1975 4026555 463 3 0 0.0000
22: B 1975 4026555 463 168 0 0.0000
23: B 1975 4026555 463 473 0 0.0000
24: B 1975 4026555 463 960 0 0.0000
25: B 1975 4026555 463 552 0 0.0000
26: B 1975 4026555 463 31 0 0.0000
27: B 1976 4155095 348 701 0 0.0000
28: B 1976 4155095 348 593 0 0.0000
29: B 1977 4137556 361 91.2 0 0.0000
30: B 1977 4137556 361 72 0 0.0000
31: B 1977 4137556 361 58 0 0.0000
32: B 1977 4137556 361 59 0 0.0000
33: B 1977 4137556 361 111 0 0.0000
34: B 1977 4137556 361 222 0 0.0000
35: B 1977 4137556 361 93.05 0 0.0000
36: B 1977 4137556 361 117 0 0.0000
37: B 1977 4137556 361 709 0 0.0000
38: B 1978 4253157 707 104.1 0 0.0000
39: B 1978 4253157 707 93.25 0 0.0000
40: B 1978 4253157 707 552 1 0.5488
My dataset is big, so a data.table solution greatly appreciated.
Thanks in advance for any help.